
Мониторинг распределённой инфраструктуры — задача, которая не решается добавлением очередного специализированного инструмента.
Большинство ИТ-команд пришли к текущему состоянию последовательно и логично: сначала Zabbix для серверов, затем отдельный инструмент для сети, APM для приложений, ещё одна система для логов. Каждое решение принималось под конкретную задачу и было обоснованным. Результат — разрозненный стек из пяти и более систем мониторинга, ни одна из которых не отвечает на главный вопрос при инциденте: что происходит с бизнес-сервисом и в каком компоненте причина.
Проблема не в качестве отдельных инструментов. Zabbix корректно отслеживает серверные метрики, сетевая система — состояние каналов, APM — транзакции приложений. Проблема в том, что эти инструменты изолированы друг от друга и не имеют общей модели зависимостей. Когда деградация сервиса вызвана нагрузкой на базу данных, которая влияет на сеть, которая замедляет API — ни один из инструментов не покажет эту цепочку целиком. Инженер выстраивает картину вручную, переключаясь между системами в условиях активного инцидента.
По данным Dynatrace, среднее крупное предприятие использует около 10 инструментов мониторинга, обеспечивая при этом полную видимость лишь в 11% своих приложений и инфраструктуры. Это прямое следствие разрозненности, а не недостаточного числа инструментов.
Описанная проблема решается на уровне архитектуры — через зонтичный мониторинг с корреляцией сервисов.
Почему инфраструктура стала структурно сложной

Рост числа компонентов — управляемая проблема. Рост взаимозависимостей между ними — нет. Именно взаимозависимости делают современную инфраструктуру структурно сложной: изменение одного элемента вызывает эффекты в компонентах, которые с ним напрямую не связаны.
Микросервисная архитектура увеличила число точек отказа при одновременном усложнении диагностики. Монолитное приложение при сбое деградирует предсказуемо. Микросервисная система — нет: задержка в одном сервисе распространяется через очереди, повторные запросы и таймауты по всей цепочке зависимостей. Среднее корпоративное приложение сегодня зависит от более чем 35 внешних сервисов и API. Без автоматической трассировки установить, в каком именно звене возник сбой, за приемлемое время практически невозможно.
Гибридная инфраструктура добавляет архитектурную и операционную разнородность. On-prem серверы, частное облако, публичные облачные платформы, контейнерные кластеры — каждый слой генерирует события в собственном формате и требует отдельного инструмента сбора данных. Интеграции между слоями в большинстве случаев либо реализованы вручную, либо отсутствуют. Единой нормализованной картины нет.
Высокая скорость изменений делает статически настроенный мониторинг хронически неактуальным. В контейнерных средах топология инфраструктуры меняется десятки раз в сутки: поды создаются и уничтожаются, сервисы масштабируются, деплоятся новые версии. Инструмент мониторинга, настроенный вчера, сегодня отслеживает сущности, которых уже нет, и не видит те, что появились.
Что это означает для бизнеса конкретно
Разрозненный мониторинг — это не технический дискомфорт для инженеров. Это операционный риск с прямым финансовым и репутационным измерением.
MTTR растёт из-за того, что локализация занимает большую часть времени инцидента. Без инструментов автоматической корреляции инженер переключается между системами, вручную сопоставляет временны́е метки и последовательно проверяет гипотезы. По данным исследования «Монк Диджитал Лаб» по итогам 2024 года, средняя продолжительность одного незапланированного простоя в российских компаниях составила четыре часа — на 20% больше, чем в 2023-м. 93% организаций зафиксировали серьёзные инциденты, затронувшие критически важные сервисы. Прямые финансовые потери от одного значимого инцидента составляют в среднем 2 млн рублей — без учёта репутационного ущерба, который оказывается не менее значительным: 65% компаний после таких сбоев фиксировали снижение доверия со стороны клиентов, 57% — ущерб для бренда.
Alert fatigue снижает надёжность дежурства. При инциденте в распределённой инфраструктуре один отказавший компонент генерирует каскад вторичных уведомлений из всех зависимых сервисов. Без автоматической группировки и подавления вторичных алертов инженер за несколько минут получает сотни несвязанных оповещений. Это не вопрос квалификации команды — это вопрос физического предела обработки информации. Пропуск критического сигнала в таком потоке является задокументированным и воспроизводимым явлением. По данным того же исследования, общее количество сбоев в российских компаниях в 2024 году выросло на 22% по сравнению с предыдущим годом — нагрузка на дежурные команды выросла пропорционально.
SLA нарушается постепенно — и без предупреждения. Деградация производительности редко выглядит как одномоментный отказ. Задержки растут на несколько процентов в неделю, длина очередей увеличивается, частота ошибок медленно растёт. Статические пороговые правила на такие тренды не срабатывают. К моменту, когда метрика выходит за порог, проблема уже несколько дней влияет на пользователей. В 2024 году 58% российских компаний столкнулись с незапланированными простоями, значительная часть которых началась именно с незамеченной постепенной деградации.
Руководство не имеет актуальной картины состояния сервисов. Разрозненные системы мониторинга предоставляют технические метрики в разных интерфейсах, которые не агрегируются в единое представление о работоспособности бизнес-сервисов. Вопросы о текущей надёжности платёжного контура, динамике доступности ключевых процессов за период или прогнозируемых рисках остаются без ответа. Инфраструктурные решения принимаются без достаточной фактической базы.
Что такое зонтичный мониторинг
Зонтичный мониторинг — архитектурный подход, при котором все существующие системы мониторинга подключаются к единому аналитическому контуру. Это не замена Zabbix, wiSLA или других инструментов: они остаются на своих местах и продолжают собирать данные в штатном режиме. Зонтичная платформа получает эти данные, нормализует их и работает поверх, не дублируя функции источников.
На входе — разнородные потоки из всех подключённых систем: метрики, события, логи, данные CMDB, информация об изменениях из Service Desk. На выходе — единая нормализованная картина инфраструктуры с привязкой каждого технического компонента к бизнес-сервисам, которые от него зависят.
Ключевой структурный элемент — ресурсно-сервисная модель (РСМ). Это автоматически построенная карта зависимостей, которая фиксирует, какой сервис использует какую базу данных, через какой сетевой узел проходит, на каком сервере работает, какие внешние API вызывает. РСМ не статична: она обновляется в реальном времени при изменениях в инфраструктуре — появлении новых компонентов, масштабировании, деплоях. Именно РСМ даёт ответ не только на вопрос «что сломалось», но и на вопрос «что именно это затрагивает» — какие сервисы под угрозой, какие SLA под риском, какие бизнес-процессы затронуты.
Принципиальное отличие зонтичного мониторинга от набора точечных инструментов — наличие единой модели зависимостей. Без неё каждый инструмент продолжает наблюдать за своим срезом инфраструктуры изолированно, и сквозная диагностика инцидента по-прежнему остаётся ручной операцией.
Наблюдаемость как фундамент для анализа
Прежде чем перейти к возможностям AIOps, важно зафиксировать одно различие, которое часто теряется в обсуждении инструментов. Мониторинг и наблюдаемость — не одно и то же.
Мониторинг отвечает на вопрос «что происходит»: сервис недоступен, CPU выше порога, задержка выросла. Наблюдаемость отвечает на вопрос «почему»: API возвращает ошибки, потому что обновление версии привело к росту нагрузки на базу данных, вследствие чего запросы на сервере №2 стали выполняться дольше обычного.
Наблюдаемость строится на трёх типах данных: метриках (числовые показатели производительности во времени), логах (детализированные записи событий с временны́ми метками) и трейсах (полный путь каждого запроса через систему с фиксацией времени на каждом этапе). Только сочетание всех трёх даёт возможность не просто зафиксировать факт проблемы, но и понять её механику.
Зонтичный мониторинг обеспечивает именно эту сквозную наблюдаемость — собирая все три типа данных из разнородных источников в единый контекст. AIOps поверх этого контекста выполняет аналитику.
Анализ корневых причин: от симптомов к источнику
Корреляция отвечает на вопрос «что связано». Root Cause Analysis — на вопрос «откуда это пошло». Это принципиально разные задачи, и AIOps решает обе.
При поступлении инцидента платформа прослеживает цепочку причинно-следственных связей по графу зависимостей: где именно началась аномалия, какие связанные сервисы она затронула и в какой последовательности. Для разграничения прямых и косвенных причин используются байесовские вероятностные модели — они вычисляют вероятность причинно-следственной связи между каждой парой событий и исключают ложные корреляции.
Важно, что анализ ведётся не только в реальном времени, но и с учётом исторической базы. Если паттерн текущего инцидента уже встречался раньше — система указывает на первопричину с высокой степенью уверенности. Если паттерн новый — строит гипотезу, взвешивая топологические, временны́е и ML-данные одновременно.
Дополнительно учитываются изменения: если незадолго до инцидента был выполнен деплой или изменена конфигурация — это автоматически попадает в контекст анализа. Связь «изменение → инцидент» — один из наиболее частых паттернов в реальных ИТ-средах, и платформа отслеживает его явно.
На практике: при массовом отказе микросервисов AIOps определяет, что проблема началась с конкретного экземпляра базы данных, который исчерпал пул соединений после деплоя новой версии приложения. Задача, которая вручную занимала часы, решается за минуты.
Обнаружение аномалий: динамика вместо статики
Традиционный мониторинг работает на правилах: «CPU > 80% — тревога». Проблема не в самих порогах — они нужны. Проблема в том, что они не учитывают контекст. 80% CPU в 3 ночи и 80% CPU в пятницу в 18:00 — это совершенно разные ситуации. 60% CPU при возросшей вдвое нагрузке — норма. 40% CPU при штатной нагрузке, но с нетипичным профилем обращений к диску — уже повод разобраться.
ML-модели в AIOps строят динамические базовые линии для каждой метрики с учётом времени суток, дня недели, исторических паттернов нагрузки и текущего операционного контекста. Аномалия — это отклонение от ожидаемого поведения, а не превышение фиксированного порога.
Artimate реализует расширенный набор детекторов:
- Детектор аномалий временны́х рядов — отклонения в числовых метриках с учётом сезонности и тренда.
- Детектор аномалий последовательности событий — фиксирует отсутствие ожидаемых событий, задержку в цепочках, нарушение порядка.
- Детектор аномалий плотности событий — выявляет аномально высокую или низкую частоту событий по сравнению с нормальным поведением; применяется в том числе для обнаружения событий в части информационной безопасности.
Это принципиально отличает подход от классического порогового мониторинга: система учится на поведении конкретной инфраструктуры, а не работает по универсальным правилам.
Прогнозирование: работа с трендами до инцидента
Реактивный мониторинг фиксирует то, что уже произошло. Предиктивная аналитика AIOps работает с тем, что произойдёт — и позволяет действовать до того, как проблема материализовалась.
Анализируя динамику потребления ресурсов, исторические паттерны инцидентов и корреляции между метриками, система формирует предупреждения заблаговременно: диск заполнится через N часов при текущем темпе роста, нагрузка на базу данных приближается к критическому порогу, паттерн метрик соответствует тому, что предшествовало аналогичному инциденту три месяца назад.
Отдельный механизм — прогноз развития инцидента. Когда инцидент уже начался, платформа строит roadmap его вероятного развития: какие сервисы могут быть затронуты следующими, как изменится нагрузка на связанные компоненты, какие SLA под угрозой. Это позволяет расставить приоритеты действий с учётом будущего влияния на бизнес, а не только текущего.
Artimate: как это реализовано на практике
Artimate — интеллектуальная AIOps-платформа, которая выступает единым интерфейсом для всех данных ИТ-мониторинга. Платформа использует инструменты ML-анализа для корреляции событий событий из систем мониторинга, объединения инцидентов в единую картину, поиска первопричин и предотвращения сбоев до их влияния на бизнес-сервисы.

Платформа реализует зонтичный мониторинг с корреляцией сервисов как готовое производственное решение — не как набор инструментов для самостоятельной сборки.
Подключение к существующим системам без разработки. Artimate интегрируется с Zabbix, wiSLA, Пульт, UDV ITM, Пульт и другими инструментами через готовые кастомизируемые коннекторы. Для нестандартных и проприетарных источников предусмотрен Low-code конструктор OIM с пошаговым wizard’ом: достаточно указать формат данных и правила маппинга, нормализацию платформа выполняет самостоятельно. Дополнительно доступен LOG-FILE агент для парсинга логов и поддержка CSV-форматов.

Обогащение контекстом. Все входящие события нормализуются и дополняются данными из CMDB и внешних справочников. Алерт с базовой меткой «высокая задержка API» автоматически получает привязку к инфраструктурному контексту (сервер, кластер, дата-центр), топологическому контексту (зависимые upstream- и downstream-сервисы) и историческому контексту (недавние деплои, плановые работы, предыдущие инциденты с этим компонентом).
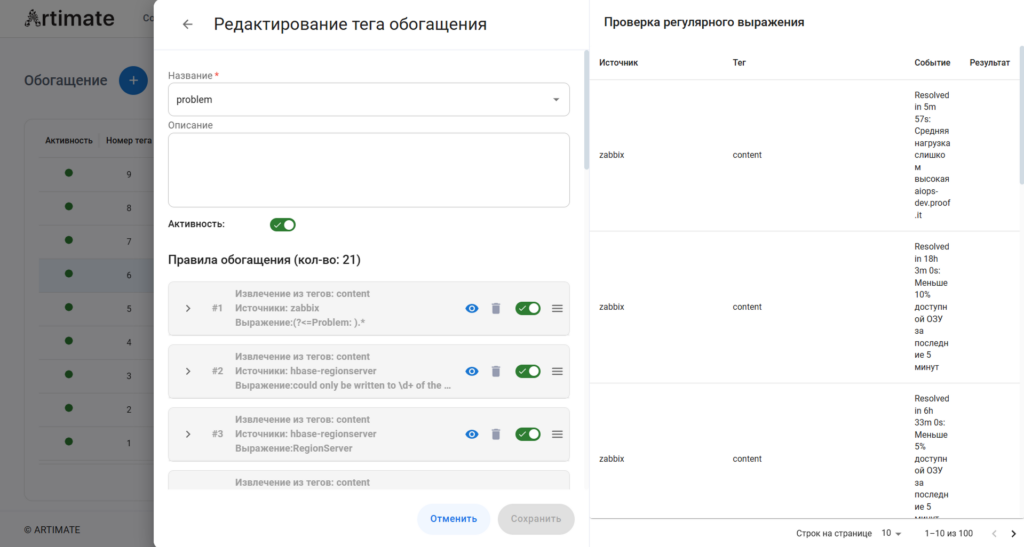
Интерактивная карта ресурсов. На основе тегов и метаданных из всех подключённых источников автоматически строится и непрерывно обновляется карта топологии — ресурсно-сервисная модель инфраструктуры. При возникновении инцидента карта сразу показывает затронутые узлы, цепочку зависимостей и масштаб влияния на бизнес-сервисы.
ML-аналитика. Поверх единого потока данных работают алгоритмические и ML-шаблоны корреляции, детекторы аномалий, RCA-движок с визуализацией причинно-следственного графа. История инцидента отражает хронологию связанных оповещений, изменений и аномалий. Прогноз развития инцидента строится автоматически с расстановкой приоритетов по влиянию на критические бизнес-сервисы.
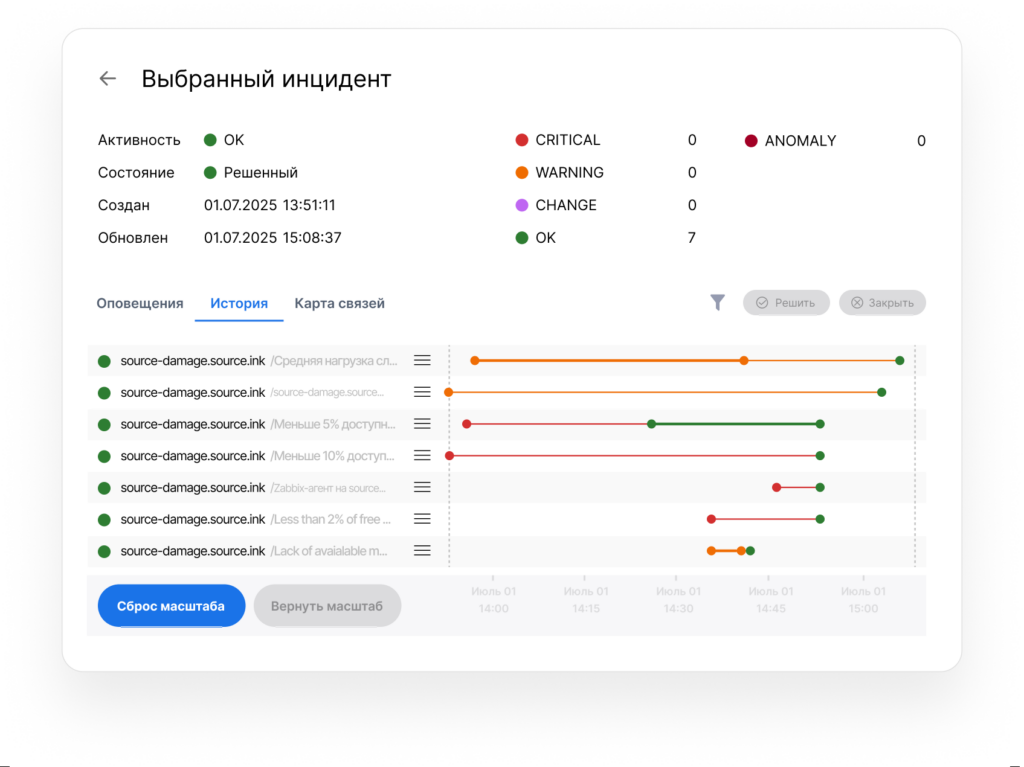
Artimate. История инцидента.
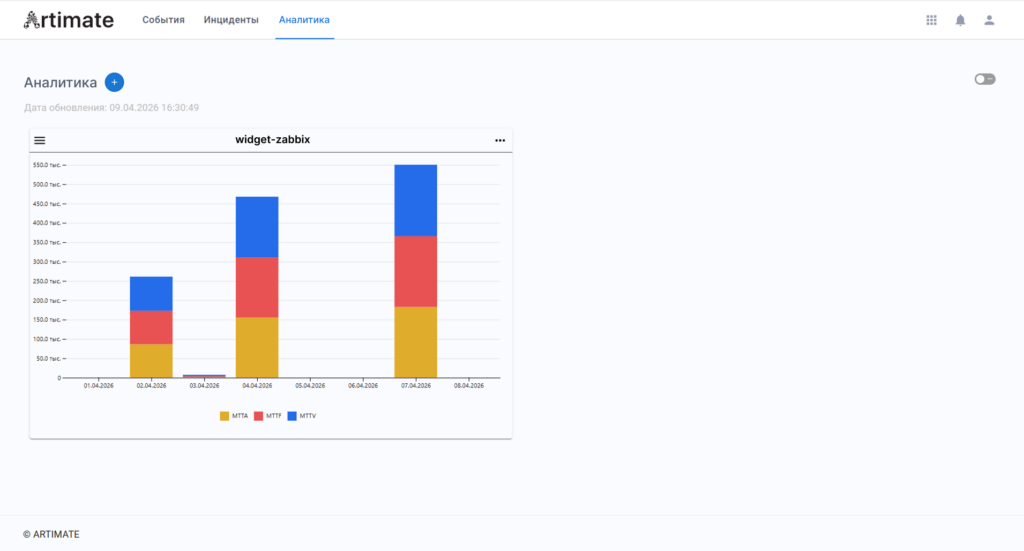
Artimate. ML-аналитика в AIOps-платформе.
Интеллектуальный ассистент ARTI. Встроенный чат-бот помогает дежурному инженеру работать с инцидентами в режиме диалога: запрашивать контекст, получать рекомендации по устранению, запускать Runbook-сценарии.
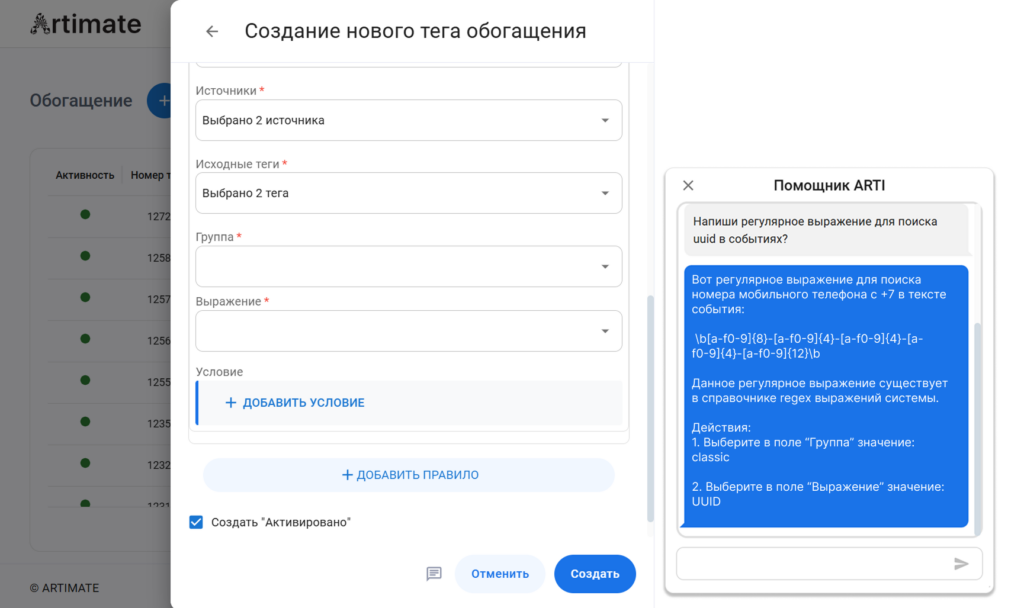
Artimate. Автоматизация ИТ-мониторинга с помощью AIOps-системы.
Чем подход Artimate отличается от стандартного AIOps
Стандартный AIOps-инструментарий покрывает базовый набор возможностей: интеграции с известными системами, корреляция по алгоритмическим шаблонам, детекция аномалий временны́х рядов, управление изменениями через внешние Service Desk. Artimate расширяет каждое из этих направлений.
По корреляции: помимо алгоритмических правил используется ML-корреляция на базе корреляционных графов — автоматическое построение карт причинно-следственных связей без ручной конфигурации.
По детекции аномалий: расширенный набор детекторов, включая детектор последовательности событий и детектор плотности — типы аномалий, которые классические мониторинги не видят вообще.
По контекстуализации: ML-кластеризация и классификация для работы с неструктурированными данными — логами, произвольными текстовыми полями, слабоструктурированными источниками. Система выделяет скрытые смыслы там, где стандартные алгоритмы видят только «сырые» строки.
Измеримые результаты
| Показатель | Результат |
|---|---|
| Снижение информационного шума | до 95% — тысячи событий в единицы инцидентов |
| Сокращение MTTR | до 50–70% за счёт автоматического RCA |
| Доступность бизнес-сервисов | SLA на уровне 99,9999% |
| Сокращение повторяющихся инцидентов | до 67% — точный RCA устраняет причину, а не симптомы |
| Снижение операционных затрат | 30–40% по данным компаний с внедрённым AIOps |
| Рост удовлетворённости клиентов | на 25–30% за счёт сокращения числа инцидентов и времени их устранения |
По прогнозу Gartner, к 2029 году 85% крупных предприятий будут использовать AI SRE-инструменты — против менее 5% в 2025 году. Компании, которые внедряют эти подходы сейчас, обучают ML-модели на реальных данных своей инфраструктуры заблаговременно — до того как это становится отраслевым стандартом.
Если хотите оценить, как зонтичный мониторинг с корреляцией сервисов будет работать конкретно на вашей инфраструктуре — запросите демо Artimate.
