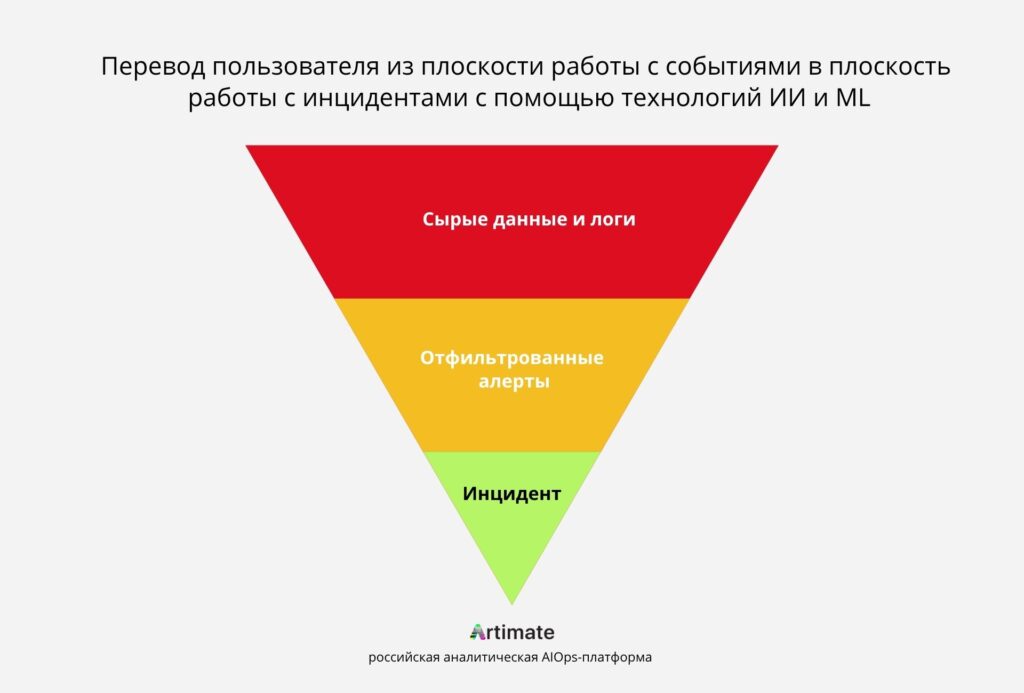
Искусственный интеллект в Observability: интеллектуальный слой, который меняет управление инцидентами
Данных в современной ИТ-инфраструктуре становится больше каждый год. Количество источников телеметрии, событий и оповещений растёт вслед за усложнением архитектур — облака, микросервисы, гибридные среды. Системы мониторинга справляются со сбором, но плохо справляются с осмыслением: они фиксируют всё, что происходит, но не помогают быстро понять, что из этого важно и почему.
Именно здесь появляется другой класс технологий. Искусственный интеллект в observability — это не замена систем мониторинга. Это интеллектуальный слой над ними: инструмент, который обрабатывает поток данных из разных источников, устраняет шум, связывает разрозненные события в единую картину и помогает инженеру быстрее выйти на причину сбоя. Его ценность — не в сборе данных, а в их интерпретации.
Мониторинг как источник нагрузки
У каждой ИТ-команды есть системы мониторинга. Но по мере роста инфраструктуры эти системы начинают производить больше событий, чем команда способна обрабатывать. Метрики, логи, трассировки, события из разных платформ накапливаются в нескольких несвязанных инструментах, каждый из которых видит только свой срез реальности.

Когда что-то идёт не так, инженер вынужден вручную переключаться между системами, восстанавливать контекст, сопоставлять данные из разных источников и самостоятельно строить картину происходящего. По данным исследования Neubird от февраля 2026 года, команды инженеров тратят на диагностику и поиск причин инцидентов в среднем 28 часов в неделю — почти три полных рабочих дня. А 40% общего инженерного времени уходит не на развитие и создание новых решений, а на управление инцидентами.
Почему сигнал теряется в шуме
Перегрузка оповещениями — главная операционная проблема инженерных команд сегодня. Исследование Grafana Observability Survey 2026 поставило «соотношение сигнала и шума» в тройку ключевых барьеров observability, а 30% респондентов назвали усталость от оповещений главной причиной замедленной реакции на инциденты.
Данные того же отчета Neubird, раскрывают механизм проблемы. 77% дежурных команд получают не менее 10 оповещений в день. При этом 57% организаций признают: более 70% этих сигналов не требуют немедленных действий. Постепенно команда адаптируется — и начинает игнорировать то, что выглядит как фон. 83% организаций фиксируют, что их инженеры регулярно закрывают оповещения без разбора.
Последствия предсказуемы. 44% компаний в прошлом году столкнулись с инцидентом, прямо связанным с проигнорированным или подавленным сигналом. Ещё 78% сообщили хотя бы об одном случае, когда оповещение не сработало вовсе — и о сбое первыми узнали клиенты, а не инженеры.
Проблема не в том, что команды работают плохо. Проблема в том, что при высоком уровне шума системы мониторинга перестают выполнять свою главную функцию: отделять важное от второстепенного.
Интеллектуальный слой: как ИИ меняет observability
Чтобы выйти из этой ловушки, недостаточно добавить ещё один инструмент мониторинга. Нужен уровень, который стоит над существующими системами и работает с их совокупным выводом — обрабатывает, анализирует и структурирует поток данных прежде, чем он попадёт к инженеру.
Именно этим является AIOps или ИИ в observability. Это интеллектуальный слой, который подключается к уже существующим системам мониторинга и добавляет к ним способность понимать контекст. Он не заменяет Prometheus, wiSLA, Zabbix или любой другой инструмент, а работает поверх них.
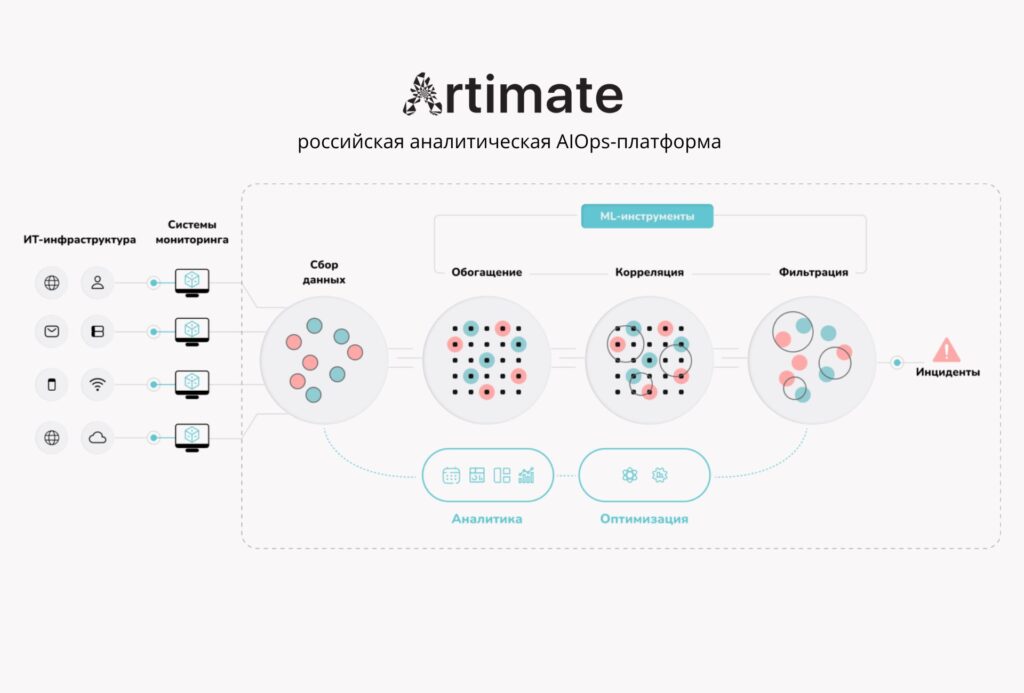
Этот слой решает несколько конкретных задач.
Фильтрация шума. Вместо статических порогов — динамические модели нормального поведения системы, адаптирующиеся к нагрузке, времени суток и плановым операциям. Всё, что не является реальным отклонением от нормы, отфильтровывается до того, как превратится в оповещение.
Дедупликация и корреляция. Одно реальное событие — например, нехватка ресурса на узле — может породить десятки сигналов из разных систем. Интеллектуальный слой объединяет их в единый инцидент, убирает дублирование и показывает не набор симптомов, а единую проблему с описанием её масштаба.
Обогащение контекстом. Каждое событие автоматически получает дополнительную информацию: бизнес-критичность затронутых сервисов, историю аналогичных инцидентов, карту зависимостей компонентов, вероятную первопричину на основе накопленных паттернов.
Приоритизация. Алгоритмы оценки рисков учитывают число затронутых пользователей, угрозу нарушения соглашений об уровне обслуживания, историческую частоту события. Инженер видит не равнозначную очередь сотни оповещений, а три действительно срочных события — и понимает, почему именно они.
По данным New Relic AI Impact Report 2026, команды с таким подходом фиксируют на 27% меньше нерелевантных оповещений. Доля информационного шума у них составляет 46% против более 70% в средах без интеллектуальной обработки.
От фильтрации к расследованию
Снижение шума меняет условия работы команды. Но когда реальный инцидент всё же происходит, задача смещается: нужно как можно быстрее понять причину и устранить её.
Здесь интеллектуальный слой берёт на себя ту часть работы, которая раньше требовала ручного труда. Вместо того чтобы инженер сам восстанавливал хронологию из разных систем, система автоматически строит временную линию событий, связывает аномалии с изменениями конфигурации, формирует карту причинно-следственных связей и выделяет зависимости между затронутыми сервисами.
Параллельно инцидент сопоставляется с историческими паттернами: система выдаёт вероятную первопричину и ссылки на решения аналогичных случаев из прошлого. Инженер приходит к инциденту не с чистого листа, а с уже собранным контекстом — и его задача сужается до проверки гипотез и принятия решений, а не до их поиска с нуля.
Измеримый эффект зафиксирован в New Relic AI Impact Report 2026: команды с ИИ-поддержкой закрывают инциденты в среднем на 25% быстрее. В пиковые периоды разница особенно заметна: 26 минут на инцидент против 50 минут без интеллектуального слоя.
Где эффект наиболее выражен
Интеллектуальный слой над мониторингом приносит наибольшую отдачу в нескольких типах сред.
Первый — разнородная инфраструктура с несколькими системами мониторинга. Чем больше источников телеметрии и чем меньше они связаны между собой, тем ценнее автоматическая корреляция и единая картина событий.
Второй — распределённые архитектуры: микросервисы, мультиоблако, гибридные среды. Именно там ручное построение карт зависимостей и поиск корневой причины занимают наибольшее время.
Третий — высокая стоимость простоя. По данным отчёта MONQ «Статистика сбоев в российских компаниях по итогам 2024 года», средняя продолжительность простоя из-за ИТ-сбоев в среднем составляет четыре часа на инцидент. Средняя стоимость одного значимого инцидента составила около 2 млн рублей, а 60% российских компаний зафиксировали прямые финансовые потери от ИТ-сбоев.
Четвёртый — команды с высокой частотой инцидентов. Организации, которые обрабатывают десятки инцидентов в месяц, выигрывают больше всего от снижения ручной нагрузки и ускорения диагностики.
Как меняется observability
Траектория развития observability в 2026 году устойчива: от накопления данных — к управляемой обработке, от реактивного реагирования — к проактивному управлению ситуацией.
Логика такая: видимость → корреляция → прогнозирование → действие. На каждом шаге задача усложняется, и именно здесь интеллектуальный слой над мониторингом позволяет пройти эту цепочку значительно быстрее.
Цель — не заменить инженера в контуре управления инцидентами. Цель — снять с него ту часть работы, которая не требует инженерной экспертизы: первичную сортировку потока событий, ручную сборку хронологии, переключение между инструментами в поисках контекста. Когда эта часть автоматизирована, специалист приходит к инциденту уже с готовой картиной — и его задача сужается до решений, которые действительно требуют его участия.
В этом и состоит роль искусственного интеллекта в observability: интеллектуальный слой, который делает поток данных управляемым, а расследование инцидентов — предсказуемым по скорости и результату.
Именно эту задачу решает Artimate — российская AIOps-платформа, которая работает как интеллектуальный слой над существующими системами мониторинга. Она объединяет данные из разрозненных источников, автоматически коррелирует события, снижает поток избыточных оповещений и ускоряет поиск первопричин инцидентов. Это позволяет инженерным командам работать не с сырым потоком сигналов, а с уже собранным и приоритизированным контекстом — и тратить время на решения, а не на их поиск.
Для бизнеса это означает сокращение времени восстановления после сбоев, снижение финансовых потерь от простоя и уменьшение нагрузки на инженерные команды. Вместо того чтобы наращивать штат дежурных специалистов или мириться с растущим числом инцидентов, компания получает управляемую операционную модель — где каждый сбой обнаруживается быстрее, диагностируется точнее и устраняется с меньшими затратами ресурса.
