Корреляционный граф в системе Artimate:от хаоса алертов к четкой картине инцидента
Что такое AIOps и зачем он нужен
Представьте дежурного инженера в 3 часа ночи. На экране — 200 алертов за последние 5 минут. Упала база данных, залогировались ошибки в трёх микросервисах, Zabbix прислал предупреждение о нагрузке на CPU, wiSLA зафиксировал деградацию SLA по двум сервисам. Все сигналы приходят одновременно, каждый требует внимания — но ни один не отвечает на главный вопрос: с чего началось, что является причиной, а что — следствием.
Такая картина характерна для любой сложной ИТ-инфраструктуры: десятки взаимосвязанных систем, сотни сервисов, тысячи метрик. Классические средства мониторинга с задачей сбора данных справляются хорошо — Zabbix, Nagios, wiSLA фиксируют отклонения и сигнализируют о них. Но анализ смысла происходящего в их задачи не входит: при сбое каждая система сообщает о своём, и оператор вынужден вручную выстраивать общую картину, последовательно исключая возможные причины.
Цена такого подхода — время. По данным индустрии, большая часть MTTR тратится не на устранение проблемы, а на её поиск. Чем сложнее инфраструктура — тем дольше диагностика и тем дороже каждая минута простоя для бизнеса.
AIOps решает именно эту задачу. Это не замена существующих инструментов мониторинга, а интеллектуальный аналитический слой над ними. Он агрегирует данные из всех источников в единое пространство, подавляет шум, группирует связанные события, обнаруживает аномалии и устанавливает причинно-следственные связи между ними. На выходе — не поток из 200 несвязанных алертов, а один структурированный инцидент с корневым источником, контекстом и рекомендацией по устранению.
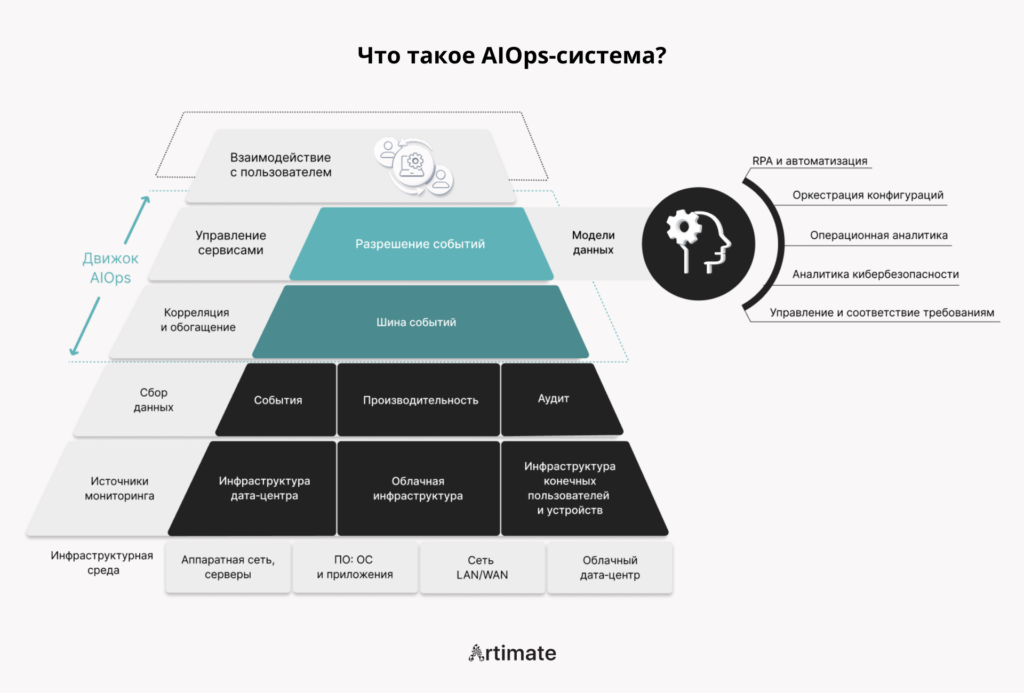
Корреляция событий и сервисов как ключевая функция
Одна из центральных возможностей AIOps — корреляция событий: система автоматически связывает алерты из разных источников, определяя, что они относятся к одному и тому же сбою. Без корреляции инженер работает с потоком разрозненных сигналов — каждый из разной системы, каждый требует отдельного внимания. С корреляцией — с одним инцидентом, у которого уже есть контекст и причина.
Важно понимать: корреляция в AIOps — это не простая группировка похожих алертов по временному окну. Поверхностная корреляция скажет: «эти события произошли примерно в одно время, вероятно, они связаны». Полноценная корреляция сервисов устанавливает направленные причинно-следственные связи. Разница между ними принципиальная:
- Временная группировка: «A и B деградировали одновременно».
- Причинно-следственная корреляция: «A деградировал первым — и именно это через 30 секунд привело к сбою B».
Второй подход отвечает не только на вопрос «что сломалось», но и на вопрос «почему». А значит, инженер сразу получает точку приложения усилий — корневую причину, а не список симптомов.
Практическая ценность корреляции раскрывается в трёх направлениях:
- Подавление шума — связанные алерты объединяются в один инцидент, очередь перестаёт расти в геометрической прогрессии при каждом крупном сбое.
- Приоритизация — система выделяет источник проблемы среди пострадавших сервисов, инженер работает с причиной, а не со следствиями.
- Скорость диагностики — вместо последовательного перебора систем специалист видит готовую цепочку влияний и сразу переходит к устранению.
Именно корреляция лежит в основе корреляционного графа — визуального инструмента, который превращает эти связи в наглядную, управляемую карту инфраструктуры.
Корреляционный граф в AIOps-системе Artimate
Корреляционный граф – это инструмент преобразования разрозненных событий в инфраструктуре в целостную картину происходящего. Задача графа – не просто показать связи между кластерами, а стать основой для объединения инцидентов, выявления аномалий и построения прогнозов развития инцидента.
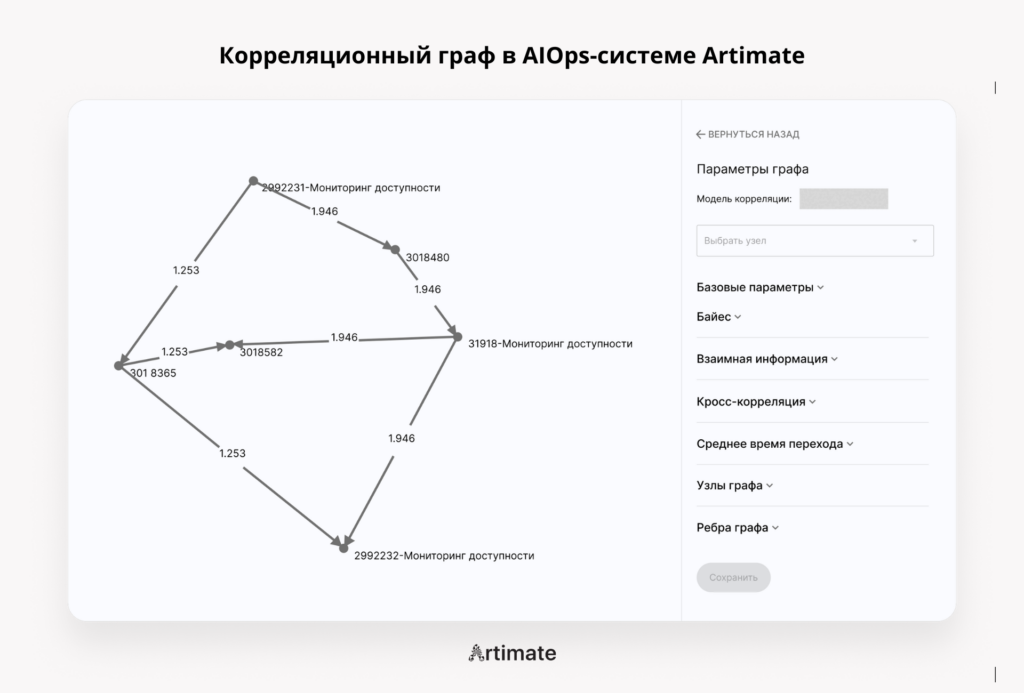
Каждый узел графа — это сервис или компонент инфраструктуры. Каждое ребро — это выявленная зависимость: если изменение метрики сервиса A статистически предшествует изменению метрики сервиса B, между ними строится направленная связь A → B.
Система корреляционного анализа построена на принципе двухэтапного подхода: сначала строится полный граф всех возможных связей между кластеризованными событиями, а затем пользователь настраивает его под свои потребности анализа. Artimate ему помогает в этом, например, по умолчанию пороги заданы таким образом, чтобы убрать визуальный шум, убрать слабые связи, которые только мешают корреляции.
Принципы работы корреляционного графа:
1. Автоматическое построение связей — система анализирует исторические данные и автоматически выявляет корреляции между событиями;
2. Интерактивная настройка — пользователь может настраивать пороги и фильтры для получения наиболее релевантного представления данных;
3. Многомерный анализ весов — каждая связь характеризуется несколькими типами весов для комплексного понимания взаимосвязей.
Этапы работы с корреляционным графом
Этап настройки / обучения
Система загружает исторические данные о событиях и строит первоначальный граф. Вершины — кластеры событий, рёбра — степень причинности между ними.
Этап эксплуатации
Пользователь через интерфейс настраивает параметры отображения, применяет пороги и фильтры. Можно получить граф, оптимально подходящий для конкретных задач анализа и соответствующий представлениям пользователя о реальных процессах в системе. Либо оставить значения порогов по умолчанию.
Каждое ребро в графе снабжено набором весов, показывающих, насколько одно событие влияет на другое.
| Название | Значение |
| Условная вероятность | Вероятность наступления события В, если известно, что наступило событие А. |
| Взаимная информация | Этот вес показывает, насколько знание о наступлении А уменьшает неопределённость относительно наступления В. |
| Кросс-корреляция | Этот вес показывает, насколько изменения в одном событии соотносятся с изменениями в другом событии во времени. Она считается более хитро, чем условная вероятность или взаимная информация. |
| Лаг | Сколько времени (в секундах) в медиане проходит между A и B. |
Окраска рёбер: различаем типы связей. После расчёта весов рёбра получают цветовую маркировку:
| Название ребра | Значение |
| Чёрные рёбра | Прямая причинность (A → B). |
| Транзитивные рёбра | Косвенная причинность (A → C через B). Отмечаются особой стрелкой синего цвета, чтобы не загромождать граф: такую связь можно проследить по цепочке чёрных рёбер. |
| Корреляционные рёбра (или «рёбра-наследники») | Между B и C есть корреляция, но нет причинности. Определяется по схожести сил связей B→C и C→B. Если ни одно событие явно не порождает другое, значит, у них есть общая причина A. Отмечаются стрелкой оранжевого цвета. |
В Artimate представленные следующие возможности по управлению графа:
- изменять названия кластеров и событий;
- редактировать пороги связей;
- настраивать значения связей: устанавливать свои или возвращать значения, полученные от ML-расчёта;
- управлять активностью кластеров (включать/отключать отображение).
Что корреляционный граф дает SRE-инженеру
Основная проблема дежурного инженера при инциденте — не отсутствие данных, а их избыток без структуры. Метрики есть, алерты есть, логи есть — но они разбросаны по разным системам и не складываются в единую картину без ручного анализа. Корреляционный граф устраняет именно этот разрыв: он не добавляет новых данных, а организует имеющиеся в понятную, читаемую форму.
Читаемый сценарий инцидента
Граф визуально отображает, как развивался инцидент: какой узел деградировал первым, на какие сервисы это повлияло и в какой последовательности. Инженеру не нужно читать сотни строк неструктурированных логов или переключаться между несколькими системами мониторинга — вся цепочка событий видна на одном экране. Цветовая маркировка рёбер сразу показывает, где прямая причинность, где косвенная, а где — общий источник у двух внешне несвязанных сбоев.
Точная локализация корневой причины
Граф разделяет источники проблемы и её последствия — это принципиально меняет логику работы с инцидентом. Без графа инженер видит 10 упавших сервисов и начинает разбираться с каждым. С графом — сразу видит, что 9 из них пострадали из-за одного узла, и направляет усилия туда. Root Cause Analysis перестаёт быть ручным процессом и становится результатом автоматического анализа направленных связей.
Понимание зоны влияния
Граф работает не только в режиме расследования, но и в режиме оценки рисков. Если деградирует конкретный сервис, инженер сразу видит, какие другие узлы находятся у него «в зоне поражения» — то есть имеют входящие рёбра от проблемного источника. Это позволяет заранее принять меры по защите критичных сервисов или предупредить смежные команды до того, как проблема распространится.
Фокус без потери контекста
Настраиваемые пороги и фильтры позволяют инженеру управлять детализацией отображения. Нужен быстрый взгляд на общую картину — убираются слабые связи, остаётся только значимая причинность. Нужен глубокий анализ конкретного узла — включаются все связи, видны даже косвенные зависимости. Граф адаптируется под задачу, а не навязывает единственный вид.
Скорость как системный результат
Все перечисленные возможности работают на одну цель — сокращение времени между обнаружением инцидента и его устранением. Инженер тратит меньше времени на диагностику, быстрее принимает решения и раньше приступает к восстановлению. В масштабе команды и инфраструктуры это даёт измеримый результат: сокращение MTTR на 60–80% по сравнению с ручным подходом.
Корреляционный граф — это точка, в которой хаос алертов превращается в управляемый процесс. На входе — сотни разрозненных сигналов из Zabbix, wiSLA, логов и агентов, каждый из которых сам по себе говорит лишь о симптоме. На выходе — структурированная карта инцидента: понятно, где началось, по какому пути распространилось и что находится под угрозой прямо сейчас.
Такой переход меняет не только скорость работы команды, но и саму логику дежурства. Инженер перестаёт быть «разгребателем очереди» и становится аналитиком, который работает с готовой картиной, а не собирает её вручную из фрагментов. За этим стоит конкретный функционал, который граф закрывает в системе Artimate:
- Выявление аномалий — граф фиксирует отклонения от исторического паттерна поведения и помогает замечать нештатные ситуации до того, как они переросли в полноценный инцидент.
- Объединение алертов — связанные события по одной теме автоматически группируются в один инцидент, очередь не растёт, приоритеты не размываются.
- Автоматический Root Cause Analysis — система определяет корневую причину на основе анализа направленных связей в графе, без ручного расследования.
- Прогнозирование развития инцидента — понимая цепочку влияний, Artimate заранее показывает, какие сервисы окажутся под угрозой при деградации конкретного узла.
Решения принимаются быстрее, приоритеты расставляются точнее, а инциденты устраняются раньше, чем успевают повлиять на бизнес-сервисы.
