Кабинет инцидента: рабочее место SRE-инженера
Вызовы управления современной ИТ-инфраструктурой
В компаниях различного масштаба ИТ-системы ежедневно генерируют огромные объемы событий из логов, метрик производительности, сетевых протоколов и пользовательских взаимодействий. Чем крупнее компания, тем больше объем данных и тем сложнее выстраивать зависимости между событиями. В масштабных инфраструктурах количество источников исчисляется десятками: Zabbix для мониторинга серверов, Prometheus для кластеров Kubernetes, Hadoop для обработки больших данных, PostgreSQL для баз знаний и так далее. Каждая система работает изолированно, создавая фрагментированный информационный ландшафт.
Информационный шум становится серьезным препятствием для эффективной работы. По данным Gartner и отраслевых практик AIOps, 90–95% оповещений оказываются ложными, дублирующимися или некритичными, что перегружает команды SRE рутинным отсевом и анализом. Традиционные пороговые алгоритмы не справляются с динамикой среды — сезонными нагрузками, фоновыми колебаниями или скрытыми аномалиями, включая изменения плотности событий и последовательные паттерны. В результате истинные угрозы маскируются среди потока уведомлений, а реакция на критичные сбои замедляется.
Поддержка инфраструктуры часто разделена между несколькими командами и сменами. Одна группа специалистов отвечает за аппаратную инфраструктуру в Zabbix, другая контролирует приложения в продакшен-среде Kubernetes, третья занимается анализом пользовательских метрик и обращений в службу поддержки. Консолидированные данные обычно сконцентрированы у руководителей центров мониторинга или ИТ-операций, что тормозит оперативную эскалацию. Без единой карты зависимостей установление причинно-следственных связей между событиями превращается в длительный процесс.
В большинстве случаев применяется реактивная модель работы. Инциденты выявляются постфактум по жалобам SLA-менеджеров или снижению трафика, а их расследование растягивается на часы или дни из-за необходимости ручного сбора данных из разрозненных систем. Ключевые показатели оказываются неудовлетворительными: MTTD превышает 30 минут, MTTR достигает 4 часов и более. Для отраслей e-com и финансовых услуг простои обходятся в 1–10 млн рублей в час.
В гибридных и мультиоблачных средах ситуация усложняется. Миграции в облако снижают видимость происходящих процессов, сетевые атаки (brute-force, DDoS) имитируют обычные нагрузки, а частые изменения конфигураций через CI/CD-пайплайны без автоматизированного трекинга провоцируют каскадные сбои. В таких условиях SRE-инженеры тратят до 70% времени на рутинный труд, что нарушает баланс между надежностью и скоростью разработки.
Что такое инцидент-менеджмент?
Инцидент-менеджмент представляет собой ключевой процесс в рамках ITSM, направленный на восстановление нормальной работы сервисов после сбоя с минимальным влиянием на бизнес-процессы. Процесс охватывает полный жизненный цикл инцидента от момента его обнаружения до закрытия и последующего анализа.
Традиционный подход к управлению инцидентами включает несколько последовательных этапов. На этапе детекции система мониторинга фиксирует отклонение от нормальных параметров работы — превышение порогов загрузки процессора, падение доступности сервиса или ошибки в логах приложений. Далее следует классификация и приоритизация: инцидент оценивается по степени влияния на бизнес и срочности устранения согласно матрице приоритетов.
На этапе диагностики и расследования команда SRE проводит root cause analysis — анализ первопричины, изучая связи между событиями, временные последовательности и зависимости компонентов инфраструктуры. После установления причины происходит устранение инцидента путем применения временных мер (workaround) или постоянного решения. Завершающий этап включает закрытие инцидента и проведение post-mortem анализа для выявления системных проблем и предотвращения повторения.
В контексте SRE-практик инцидент-менеджмент эволюционирует в сторону автоматизации и проактивности. SRE-инженеры фокусируются на снижении повторяющегося ручного труда, который можно автоматизировать, и на поддержании баланса между надежностью системы и скоростью внедрения новых функций. Цель состоит не только в быстром реагировании на сбои, но и в их предотвращении через мониторинг SLI и соблюдение SLO.
AIOps меняет подход к управлению инцидентами, используя возможности искусственного интеллекта и машинного обучения для автоматизации операционных задач. AIOps-платформы автоматизируют корреляцию событий из множественных источников, выявляют скрытые аномалии через ML-модели (временных рядов, плотности, последовательностей), строят динамические топологии зависимостей и прогнозируют развитие инцидентов. По данным аналитических агентств, внедрение AIOps позволяет снизить информационный шум на 80–95% и сократить MTTR на 50–70%, переводя команды из режима реактивного тушения пожаров в проактивное управление надежностью.
Artimate: российская AIOps-платформа для управления инцидентами
Artimate — это интеллектуальная AIOps-платформа, использующая искусственный интеллект и машинное обучение для автоматической обработки и анализа большого объема событий из систем ИТ-мониторинга, объединения инцидентов в единую картину, визуализации причинно-следственных связей и прогнозирования сбоев.
Архитектура платформы построена на принципах зонтичного мониторинга — агрегации данных из всех существующих систем наблюдения без необходимости их замены. Artimate интегрируется с широким спектром источников: системами мониторинга (Zabbix, Nagios, Prometheus, SolarWinds), платформами виртуализации и контейнеризации (VMware, Kubernetes), базами данных (PostgreSQL, ClickHouse, HBase), системами обработки больших данных (Hadoop) и так далее. Для подключения используются low-code OIM-коннекторы, позволяющие настроить интеграцию без глубоких технических знаний, а также универсальный парсер LOG-FILE для обработки неструктурированных логов.
В основе платформы лежат ML-модели, которые выполняют несколько ключевых функций. Модели детекции аномалий выявляют отклонения в временных рядах метрик, изменения плотности событий и аномальные последовательности, которые невозможно обнаружить традиционными пороговыми правилами. Кластеризация событий группирует схожие инциденты, снижая дублирование и позволяя выявлять паттерны. Корреляционные графы строят динамическую карту зависимостей между компонентами инфраструктуры, автоматически устанавливая причинно-следственные связи.
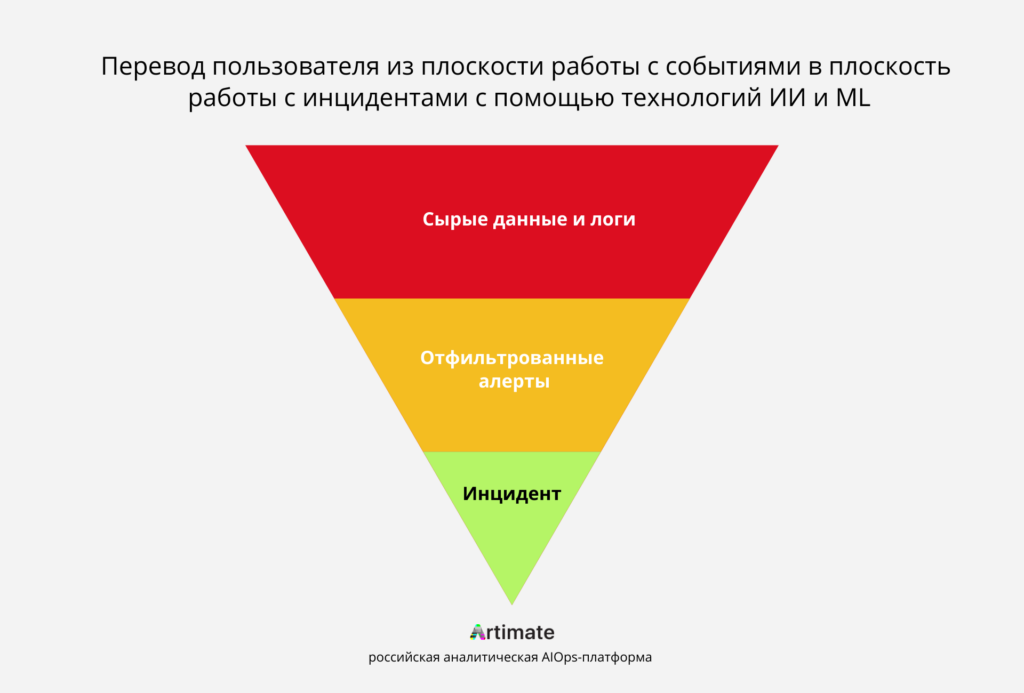
Перевод пользователя из плоскости работы с событиями в плоскость работы с инцидентами с помощью технологий ИИ и ML.
Платформа поддерживает автоматизацию на всех уровнях. Система самостоятельно определяет критичность инцидентов, выбирает ответственных специалистов на основе правил и истории обработки, запускает цепочки автоустранения для типовых проблем. Встроенный чат-бот ARTI предоставляет рекомендации по устранению инцидентов на основе базы знаний и предыдущих кейсов, предлагая готовые runbooks для стандартных сценариев.
Прогнозирование развития инцидентов — одна из ключевых возможностей платформы. Artimate анализирует текущее состояние инфраструктуры, оценивает риски и строит roadmap потенциальных сбоев с указанием вероятности и возможного влияния на бизнес-сервисы. Это позволяет SRE-командам переходить от реактивного реагирования к проактивному предотвращению.
Рабочий кабинет инцидента AIOps-платформы Artimate
Кабинет инцидента Artimate — это инструмент, предназначенный для централизованного управления и мониторинга инцидентов.
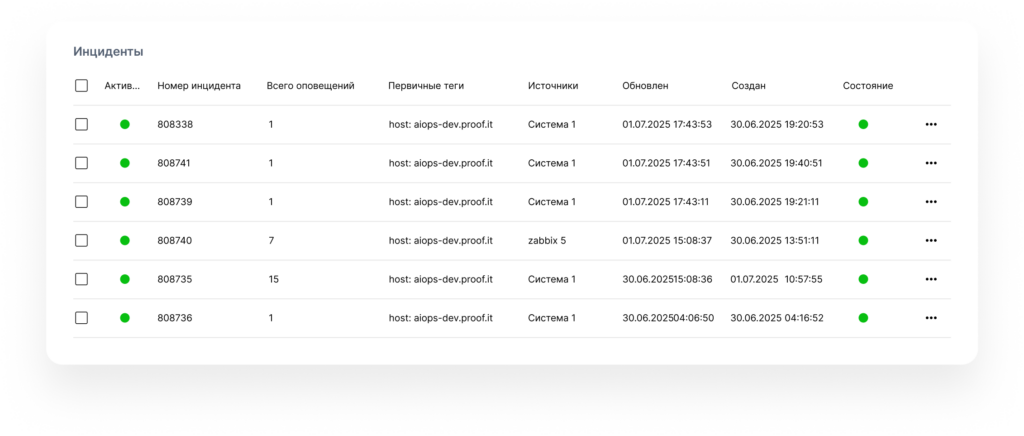
Доступ к кабинету осуществляется из главного дашборда, который отображает общий список инцидентов с предпросмотром информации по текущим инцидентам в состояниях “Открыт” и “Решен”. Также на странице предусмотрены фильтры по полям:
- Источники
- Статус
- Состояние
Платформа предлагает два режима работы со списком инцидентов. Онлайн-режим позволяет наблюдать за формированием инцидентов и их развитием в реальном времени, отфильтровывая уже закрытые события и снижая визуальный шум. Это помогает командам быстрее реагировать на текущие проблемы и концентрироваться на актуальных задачах. Архивный режим предназначен для анализа исторических данных по завершенным инцидентам, что полезно при проведении post-mortem анализа и выявлении повторяющихся паттернов сбоев.
Рабочий кабинет инцидента отображает его полную историю, состав аварии, изменений связанных аномалий, карту связей, задействованных ресурсов, журнал событий.
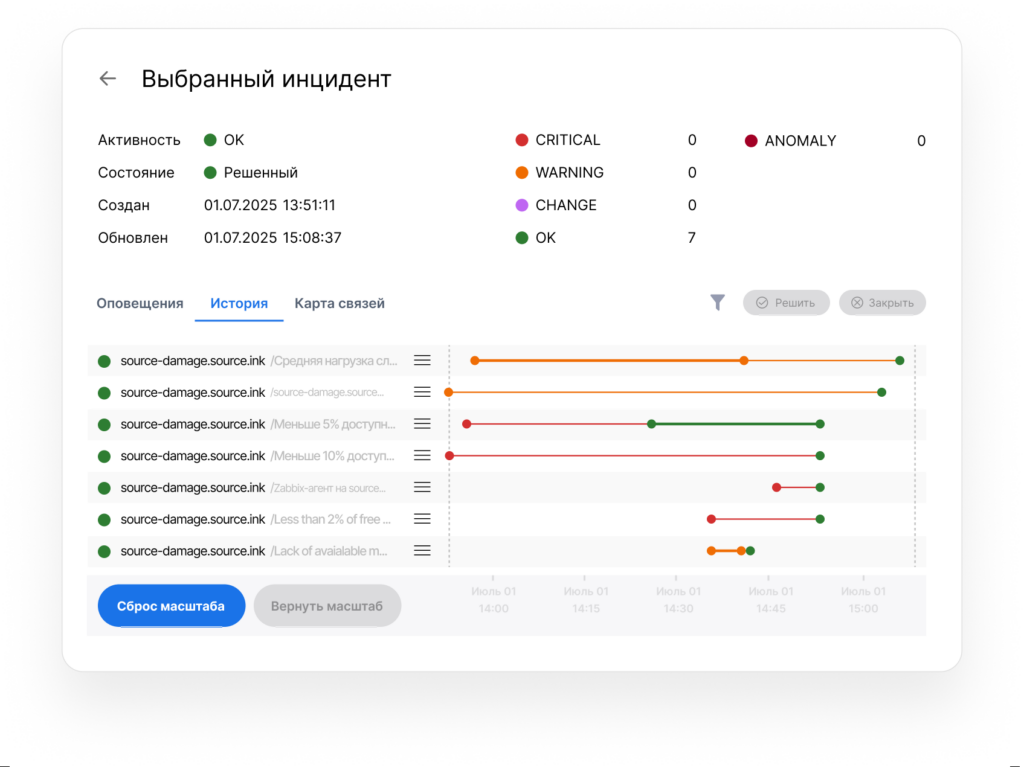
Artimate: рабочий кабинет инцидента.
При выборе конкретного инцидента открывается детальный кабинет с полной информацией об инциденте:
- Статус, состояние, даты создания и последнего обновления, легенда с количеством оповещений в инциденте в состояниях “Решен” и “Открыт”, фильтрация по оповещениям;
- Обзор оповещений по инциденту содержит детализированный список на основе найденных триггеров в событиях. Оповещения формируются на основе найденных триггеров в событиях. Триггеры могут быть очевидными, например, если статус события CRITICAL или WARNING, так и скрытыми от пользователя, которые вычисляет модель аномалии;
- Временная шкала, также известная как timeline, представляет собой события, входящие в оповещение от момента его открытия до решения. Она позволяет специалистам отслеживать последовательность действий и помогает выявить зависимости между различными этапами развития инцидента;
- Карта связей — один из наиболее мощных инструментов кабинета. Она визуализирует взаимосвязи между различными элементами инцидента: серверами, приложениями, сетевыми компонентами, базами данных. Связи строятся по трем механизмам: корреляционному графу, который анализирует временные и статистические зависимости между событиями; алгоритмическим шаблонам корреляции, основанным на типовых сценариях; ML-моделям аномалий, выявляющим нетипичные паттерны взаимодействия. Карта помогает установить причинно-следственные связи и выявить цепочки событий, приводящие к развитию инцидента. Кроме того, она прогнозирует вероятность потенциальных проблем, показывая, какие компоненты находятся в зоне риска.
Функционал управления инцидентами включает как ручные, так и автоматизированные действия. SRE-инженер может вручную решить инцидент (перевести в статус решенного после устранения), закрыть его (зафиксировать окончательное завершение) или объединить несколько связанных инцидентов в один для комплексного анализа. Параллельно настраиваются правила автоматического решения, закрытия и объединения на основе условий: типа оповещений, длительности, затронутых компонентов, результатов автопроверок.
Преимущества для SRE-инженера и бизнеса
Внедрение кабинета инцидента приносит конкретные измеримые результаты как для операционных команд, так и для бизнеса в целом. Для SRE-инженеров ключевое преимущество заключается в оптимизации времени. Вся необходимая информация по инциденту собрана в едином интерфейсе: метрики, логи, зависимости, история действий. Это исключает необходимость переключаться между десятками систем мониторинга, собирать данные вручную и тратить часы на поиск взаимосвязей.
Поддержка принятия решений осуществляется через визуализацию полной картины инцидента. Таймлайн показывает хронологию и динамику развития, карта связей выявляет первопричину и зависимые компоненты, прогнозные модели указывают на риски дальнейшей эскалации. SRE-инженер видит не только симптомы проблемы, но и ее корневую причину, что критически важно для эффективного устранения. Ускорение root cause analysis приводит к снижению MTTR на 50–70% по сравнению с традиционными подходами.
Снижение информационного шума — еще одно важное преимущество. ML-модели фильтруют ложные и дублирующиеся оповещения, кластеризуют связанные события в единые инциденты, выделяют действительно критичные проблемы. Вместо потока тысяч оповещений SRE получает десятки структурированных инцидентов с приоритетами и контекстом. По оценкам Gartner и кейсам внедрения, количество оповещений, требующих ручной обработки, снижается на 90–95%.
Проактивное управление становится возможным благодаря прогнозированию сбоев. Artimate анализирует тренды метрик, выявляет ранние признаки деградации компонентов, предсказывает развитие инцидентов с оценкой влияния на бизнес-сервисы. Это позволяет предотвращать сбои до того, как они повлияют на пользователей, минимизируя риски нарушения SLA и репутационные потери.
Для бизнеса основные преимущества заключаются в повышении доступности сервисов и снижении операционных издержек. Быстрое обнаружение и устранение проблем позволяет обеспечивать высокие показатели SLA — до 99,999%. Сокращение времени простоя на 70% напрямую отражается на финансовых результатах компании. Особенно это важно для отраслей электронной коммерции, финансовых услуг и телекоммуникаций, где каждый час недоступности сервисов приводит к потерям в миллионы рублей и негативно влияет на репутацию бренда.
Оптимизация операционных расходов достигается за счет автоматизации рутинных операций и более эффективного использования ресурсов. Платформа выявляет «зомби-ресурсы» — неиспользуемые серверы и сервисы, — позволяя рационализировать инфраструктуру. Снижение нагрузки на SRE-команды дает возможность перераспределить усилия с рутины на стратегические задачи: улучшение архитектуры, внедрение DevOps-практик, повышение надежности.
Система поддерживает ролевую модель, позволяя настраивать права доступа для различных уровней специалистов — от операторов мониторинга до архитекторов инфраструктуры. Это ускоряет эскалацию, улучшает коммуникацию между командами и повышает общую операционную зрелость организации.
