Зачем AIOps-платформе нужна своя LLM
Рынок языковых моделей растет стремительно: ChatGPT, GigaChat, YandexGPT — кажется, достаточно подключить любую из них через API и получить «умного помощника» в продукте. Подход с внешней моделью дает быстрый старт, но имеет ограничения: данные уходят за периметр, модель не знает специфики конкретной инфраструктуры, а качество ответа зависит от того, насколько полно удалось описать контекст в промпте. Для крупного бизнеса и госсектора передача данных во внешние сервисы часто неприемлема ни юридически, ни организационно.
Собственная модель, дообученная на узкоспециализированных данных, решает конкретные задачи точнее — и делает это внутри закрытого контура.
В версии 1.6.0 мы дообучили собственную языковую модель и начали встраивать ее в ARTIMATE для оптимизации ряда ключевых сценариев. На первом этапе интеграции были определены четыре направления для улучшения. Рассмотрим их подробнее:
Поиск по внутренней базе знаний компании (RAG)
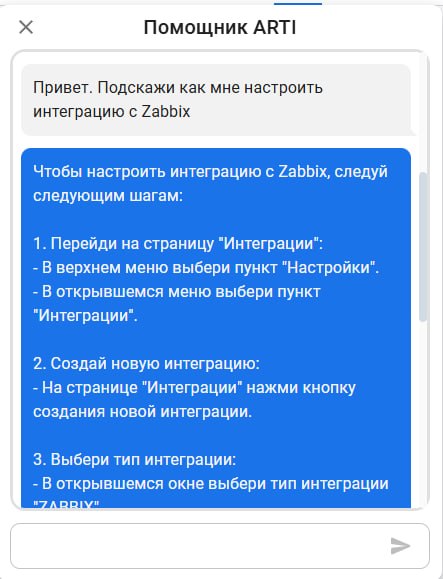
Раньше инженер, которому нужна была инструкция — например, как настроить интеграцию с Zabbix— переключался между вкладками wiki и внутренними хранилищами документации, тратя на поиск несколько минут. Теперь LLM подключена к единому корпоративному хранилищу: пользователь задает вопрос на естественном языке прямо в интерфейсе Artimate и получает точный ответ с пошаговой инструкцией.
В результате сокращается время на поиск по базе знаний, а работа с документацией становится частью одного рабочего окна.
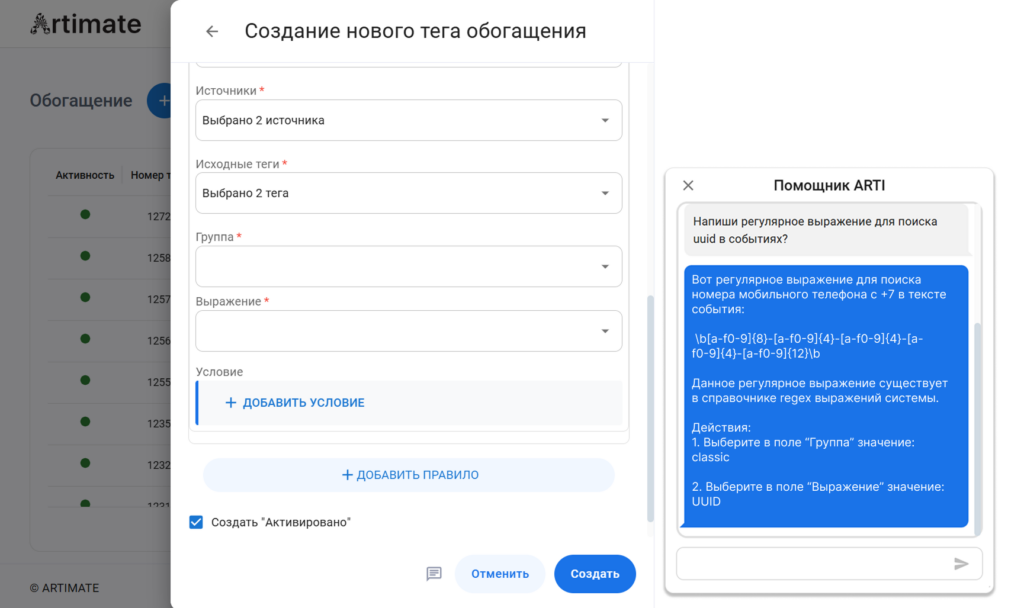
Подбор регулярных выражений
Настройка правил обогащения событий требует умения составлять регулярные выражения — навыка, которым обладают не все специалисты по мониторингу. Теперь в диалоговом окне достаточно описать задачу словами: «Составь регулярное выражение для поиска IP-адресов в событиях». LLM анализирует запрос, сверяет его с существующим справочником Regex и либо предлагает оптимальное готовое решение, либо генерирует новое выражение с пояснением логики, исключая ошибки при ручном копировании сложных конструкций.
В результате настройка обогащения ускоряется, снижается зависимость от узких технических навыков и уменьшается риск ошибок при ручной работе с шаблонами.
Присвоение кластерам имен на основе входящих в них событий в модели кластеризации
Стандартные алгоритмы кластеризации часто формируют технические группы с обезличенными названиями вроде cluster47, которые не помогают быстро понять, что именно произошло в системе. Чтобы упростить работу инженера, LLM анализирует состав каждого кластера и подбирает для него смысловое название, отражающее общий характер входящих событий. Пользователь запускает переименование прямо на странице модели кластеризации после расчета и получает кластеры с понятными названиями, которые проще использовать в анализе и при работе с корреляционным графом.
В результате не нужно вручную просматривать содержимое каждого кластера, а структура инцидентов становится понятнее с первого взгляда
Оптимизация кластеров
Даже после расчета модели кластеризации остается возможность улучшить маски и повысить качество группировки событий. Если делать это вручную, специалисту нужно глубоко погружаться в контекст каждого кластера, сопоставлять события между собой и тратить на анализ много времени. LLM упрощает этот процесс: она получает список событий, видит их распределение по кластерам и на основе взаимосвязей предлагает, какие кластеры стоит объединить, а какие — разделить. Пользователь отправляет запрос на оптимизацию и получает понятное объяснение причин, например: «Рекомендуется объединить cluster1 и cluster2, так как оба лога относятся к ошибкам HDFS при распределении блоков».
В результате повышается точность модели кластеризации, а сама система постепенно становится более “умной”: инженеры получают экспертные подсказки там, где раньше уходили часы на ручное исследование.
Что дальше
Релиз 1.6.0 — только первый этап встраивания LLM в платформу. В ближайших планах – расширить применение LLM на создание сущностей по запросам через диалоговое окно и подготовку отчетов с анализом инцидентов.
