Мониторинг ИТ-инфраструктуры: когда все под контролем
Введение
В 2025 году любая компания по сути превращается в ИТ‑бизнес: продажи зависят от интернет‑витрины, клиентский сервис — от мобильного приложения, а репутация — от скорости ответа API. При этом‑же каждая минута простоя критичных систем обходится в среднем 350 000 — 600 000 рублей, а крупным e‑commerce‑площадкам — в несколько миллионов. Добавьте к этому гибридные облака, микросервисы, распределенные команды и релизы «по клику» , и станет ясно: управлять такой экосистемой «на ощупь» больше невозможно. Нужен инструмент, который видит сразу все: нагрузку процессора в собственном ЦОД, задержки в Kubernetes‑кластере, всплеск ошибок в платежном шлюзе и даже снижение конверсии на фронтенде. Этим инструментом и является современный ИТ‑мониторинг.
IT-мониторинг — это комплексный процесс, включающий сбор и обработку миллионов метрик, их корреляцию с бизнес‑показателями и автоматическое реагирование еще до того, как инцидент скажется на клиентах. Правильно выстроенная система превращается в цифровой «пункт управления полетами»: она мгновенно замечает отклонения, сигнализирует точке ответственности, а порой самостоятельно перезапускает сервис или масштабирует ресурсы, не дожидаясь вмешательства человека.
В этом материале мы разберем, как устроен мониторинг IT-инфраструктуры предприятия: от фундаментальных уровней сбора телеметрии до аналитики на базе искусственного интеллекта. Если ваша цель сохранить доступность 99,99 % и одновременно оптимизировать расходы на инфраструктуру, эта статья даст вам четкую дорожную карту.
Что такое ИТ-мониторинг?
Определение ИТ-мониторинга
ИТ‑мониторинг — это непрерывный процесс сбора, обработки и анализа технических и бизнес‑метрик, который позволяет в режиме реального времени понимать, насколько корректно работают ИТ-оборудование и цифровые сервисы организации. На практике речь идет о контроле тысяч узлов: от серверов в собственном ЦОД до контейнерных кластеров в облаке и API‑шлюзов, обеспечивающих взаимодействие с клиентами.
Цель проста и при этом стратегически важна: своевременно понимать, всё ли работает так, как задумано, и успевать реагировать до того, как локальная неполадка перерастет в инцидент, влияющий на пользователей или бизнес-показатели.
Базовый мониторинг осуществляется путем проверки работы устройств, а более продвинутый мониторинг позволяет получить подробное представление о состоянии работы, например, о среднем времени отклика, количестве экземпляров приложений, количестве ошибок и запросов, использовании процессора и доступности программных приложений. Мониторинг осуществляется непрерывно или периодически — ежедневно, еженедельно или ежемесячно. Данные, собранные системами IT-мониторинга, позволяют организации получить глубокое представление об ИТ-среде.
Например, федеральный ритейлер, управляющий более чем 4 000 кассовых терминалов, использует систему мониторинга, чтобы отслеживать загрузку каналов связи, задержки в API‑запросах и исправность POS‑оборудования. Как только задержка превышает 300 мс или теряется соединение с кассой, инженер получает алерт в Telegram и через интеграцию с сервис‑деском создается тикет. Это позволяет устранять неполадки до того, как они затронут покупателей.
Как работает ИТ-мониторинг
IT-мониторинг реализуется по-разному в зависимости от типа. Однако в общем виде он обычно охватывает три основных элемента:
Фундамент. Инфраструктура — это самый нижний уровень программного стека, который занимается мониторингом физических и виртуальных устройств, таких как серверы, процессоры или виртуальные машины.
Программное обеспечение. Иногда называемый уровнем мониторинга, этот раздел анализирует данные с устройств из раздела “Фундамент”. Здесь собираются такие данные, как использование процессора, нагрузка, память или количество запущенных виртуальных машин.
Интерпретация. Собранные данные и метрики интерпретируются и представляются в виде графиков или диаграмм данных, часто на панели GUI. Часто это достигается за счет интеграции с инструментами, которые специально ориентированы на визуализацию данных.
Можно выделить еще и другие инструменты, используемые в ИТ-мониторинге:
Инструменты наблюдения — это базовый тип инструментов, которые отслеживают эффективность работы программного обеспечения.
Инструменты анализа берут данные наблюдений и далее анализируют их, чтобы определить, где и почему возникают проблемы с ИТ.
Инструменты взаимодействия направлены на то, чтобы на основе данных, полученных от инструментов наблюдения и анализа, предпринять действия, такие как генерация предупреждений или запуск другого оборудования или программного обеспечения
Типы ИТ-мониторинга
Существует большое количество типов ИТ-мониторинга, которые организация может использовать на каждом уровне своего ИТ-ландшафта:
Мониторинг ИТ-инфраструктуры. Мониторинг ИТ-инфраструктуры — это процесс базового уровня, в ходе которого собираются и анализируются показатели, касающиеся аппаратного и программного обеспечения ИТ-среды. Инструменты мониторинга инфраструктуры обеспечивают эталон идеальной работы физических систем, что облегчает процесс тонкой настройки и сокращения времени простоя, а также позволяет ИТ-командам обнаруживать сбои.
Мониторинг серверов и систем охватывает специализированные инструменты, которые непрерывно отслеживают ключевые метрики производительности серверных узлов и связанных с ними инфраструктурных компонентов. Каждый сервер контролируется индивидуально, а затем агрегированные данные анализируются на предмет производительности сети. Такой подход позволяет быстро выявлять узкие места, корректировать конфигурации и поддерживать стабильность всей инфраструктуры.
Облачный мониторинг. Возможности и опции облачного мониторинга также расширились. С помощью мониторинга можно получить информацию о некоторых показателях, таких как использование процессора, памяти и хранилища, чтобы оценить эффективность работы своих приложений. На физический актив ставится агент мониторинга, который собирает данные и отправляет в систему облачного мониторинга.
Мониторинг сети. Сетевой мониторинг позволяет выявить проблемы, вызванные медленной работой или отказом сетевых компонентов, а также нарушениями безопасности. Показатели включают время отклика, время безотказной работы, сбои в запросах состояния и проверки HTTP/HTTPS/SMTP.
Мониторинг безопасности. Этот тип мониторинга направлен на обнаружение и предотвращение угроз, как правило, на сетевом уровне. Он включает в себя мониторинг сетей, систем и конечных точек на предмет уязвимостей, ведение журнала доступа к сети и выявление моделей трафика для поиска потенциальных нарушений.
Мониторинг производительности приложений (APM). APM собирает показатели производительности программного обеспечения, основанные как на опыте конечных пользователей, так и на потреблении вычислительных ресурсов. Примеры показателей, предоставляемых APM, включают среднее время отклика при пиковой нагрузке, данные об узких местах в производительности, а также время загрузки и отклика. Мониторинг приложений входит в сферу управления производительностью приложений — концепции, которая подразумевает более широкий контроль уровня производительности приложений.
Мониторинг деловой активности. Мониторинг деловой активности направлен на измерение и отслеживание бизнес-показателей. Этот тип мониторинга помогает оценить показатели производительности за более длительные периоды времени. Эти инструменты отслеживают такие показатели, как загрузка приложений, продажи в Интернете и другие показатели, например объем веб-трафика.
Что такое мониторинг ИТ‑инфраструктуры, и зачем он нужен бизнесу?
Определение мониторинга ИТ-инфраструктуры
Мониторинг ИТ‑инфраструктуры — это непрерывное наблюдение и анализ работы всех ключевых компонентов цифровой среды компании: серверов, сетевых устройств, виртуальных машин, баз данных, приложений и сервисов. Специализированное ПО автоматически собирает метрики, анализирует их и в случае отклонений сразу оповещает ответственных специалистов, а в ряде случаев инициирует автоматическое исправление (перезапуск сервиса, переключение на резервный канал, масштабирование ресурса). По сути, мониторинг выступает «системой раннего предупреждения», позволяя команде реагировать еще до того, как локальная проблема перерастет в инцидент, влияющий на пользователей и бизнес‑показатели.
Мониторинг IT-инфраструктуры предприятия принято рассматривать на двух взаимодополняющих уровнях: мониторинг оборудования и мониторинг ПО (приложений).
Какие задачи решает мониторинг IT инфраструктуры
Ключевая цель мониторинга IT‑инфраструктуры — гарантировать бесперебойную и качественную работу всех систем, предупреждать сбои и сводить время простоя к минимуму. По сути, мониторинг играет роль «сигнализации» для цифрового хозяйства компании: он фиксирует малейшие отклонения в производительности или доступности ресурсов, мгновенно уведомляет ответственных специалистов и, при необходимости, автоматически выполняет корректирующие действия. Благодаря этому сбои локализуются ещё на зародышевой стадии, сервисы остаются доступными для пользователей, а бизнес избегает прямых финансовых потерь и ущерба репутации.
Рассмотрим конкретные задачи мониторинга IT-инфраструктуры более подробно:
Контроль состояния оборудования
Мониторинг начинает работу с «физики»: серверов, сетевых маршрутизаторов, систем хранения, источников бесперебойного питания. Система отслеживает температуру процессоров, скорость вращения вентиляторов, износ дисков, уровень заряда батарей в ИБП и даже вибрации в стойке. Когда, к примеру, жесткий диск начинает выдавать SMART‑ошибки, мониторинг фиксирует рост параметра Reallocated Sectors Count и мгновенно поднимает алерт — инженер меняет диск еще до фактической потери данных. Такой контроль продлевает срок службы оборудования и экономит бюджет на экстренные закупки.
Анализ и обработка данных
Собрать телеметрию — полдела; важно уметь превратить миллионы сырых точек в осмысленные выводы. Система агрегирует метрики, нормализует логи, устраняет дубликаты, применяет дедупликацию событий и скользящие окна, чтобы выявить тренды: например, постепенное увеличение среднего времени отклика API на 2 % в неделю. На основе прогнозных моделей (ARIMA, Prophet) мониторинг предсказывает, когда ресурс достигнет критического порога, и предлагает план работ. Это превращает реактивное «тушение пожаров» в плановое развитие инфраструктуры.
Обеспечение безопасности
Отдельный пласт наблюдаемости сосредоточен на кибер‑угрозах. Мониторинг сравнивает поведение хостов с эталонными профилями, обнаруживает внезапные всплески входящих соединений, нетипичные запросы к критичным таблицам баз данных или попытки несанкционированного повышения прав доступа. Интеграция с SIEM‑платформой автоматически обогащает алерты контекстом: IP‑адрес атаки, геолокация, хеш вредоносного файла. Если правило выявляет ботнет‑трафик, система тут же изолирует сетевой интерфейс через SDN‑контроллер, переводя инцидент из разряда «KRIT» в «INFO» за считанные секунды.
Управление событиями и оповещения
Сырые события превращаются в понятные инженеру сигналы: триггеры с приоритетами, SLA‑таймерами и маршрутизацией. Мониторинг сам определяет ответственную группу по CMDB, отправляет уведомление в Slack или Telegram, создает тикет в ServiceNow и отслеживает эскалацию, если алерт остается без реакции. При повторяющихся событиях (например, три алерта «диск заполнен > 90 %» за сутки) система объединяет их в инцидент, чтобы не перегружать «дежурку» шумом.
Оптимизация производительности
Наблюдаемость дает точные данные о загрузке ресурсов и поведении пользователей. Это основа для динамического масштабирования: автоматика увеличивает число подов в Kubernetes при росте очереди сообщений или включает еще один экземпляр базы данных перед отчетным периодом. Анализ длительности SQL‑запросов выявляет «тяжёлые» JOIN‑ы; после изменения индексов время выполнения падает с 1,2 с до 120 мс, а SLA по latency выполняется с запасом.
Отчетность и визуализация
Разным ролям — разный уровень детализации. CTO на ежеквартальном совещании видит сводку: среднее выполнение SLA = 99,95 %, пять критических инцидентов, тренд затрат на облако + 7 % QoQ. Инженеру SRE нужен живой дашборд, где каждая метрика кликается до графика‑источника. Маркетологу важен собственный виджет — конверсия из «корзины» в «оплату» коррелирует с ошибками оплаты. Четкая визуализация превращает сложные цифры в удобный инструмент принятия решений.
Выявление первопричин неисправностей (Root Cause Analysis)
Когда происходит сбой, важно не просто «потушить» симптом, а понять корень проблемы. Корреляционные графы, топологии сервисов и трассировка распределенных запросов позволяют отследить путь: фронтенд → API‑шлюз → сервис платежей → БД. Если задержка возникла из‑за переполненной очереди RabbitMQ, мониторинг выделяет этот узел красным, показывая зависимые сервисы и затронутые бизнес‑операции. Такой RCA сокращает MTTR с часов до минут и помогает провести пост‑инцидентный разбор по методике «пяти почему», чтобы исключить повторение проблемы.
Как работает мониторинг IT-инфраструктуры

Сбор и агрегирование данных
Инструменты мониторинга собирают данные из различных областей ИТ-среды, таких как серверы, сетевые устройства, виртуальные машины и некоторые программные пакеты. Эти данные могут включать в себя показатели производительности, в том числе коэффициент использования процессора, пропускную способность сети, использование дискового пространства и анализ времени отклика.
Анализ данных и выявление аномалий
После сбора данных система анализирует тенденции производительности и сравнивает их с заданными пороговыми значениями. Например, если в течение длительного периода времени загрузка процессора достигает 95 %, инструмент мониторинга распознает это как потенциальное узкое место. Продвинутые решения используют аналитику на основе искусственного интеллекта для выявления закономерностей, которые могут указывать на будущие сбои или риски безопасности.
Автоматические оповещения и уведомления
При обнаружении проблемы ИТ-командам отправляются оповещения в режиме реального времени по электронной почте, мессенджеры или интегрированные панели мониторинга. Эти оповещения определяют приоритетность критических проблем, таких как сбои сервера или отказы приложений, чтобы команды могли быстро отреагировать. Настраиваемые пороги оповещений помогают снизить «усталость от оповещений», отсеивая незначительные колебания, которые не требуют немедленных действий.
Визуализация
Вместо того чтобы вручную просматривать журналы, современные платформы мониторинга предлагают интуитивно понятные информационные панели, позволяющие в режиме реального времени видеть состояние системы. Эти панели отображают ключевые показатели производительности, тенденции развития системы и потенциальные проблемы, помогая ИТ-командам принимать решения на основе данных, а не реагировать на инциденты вслепую.
Чтобы решать перечисленные задачи на практике, одной концепции наблюдаемости недостаточно — нужно правильно организовать сбор телеметрии. На этом этапе компании выбирают между двумя архитектурными подходами, которые определяют глубину данных, сложность развертывания и накладные расходы:
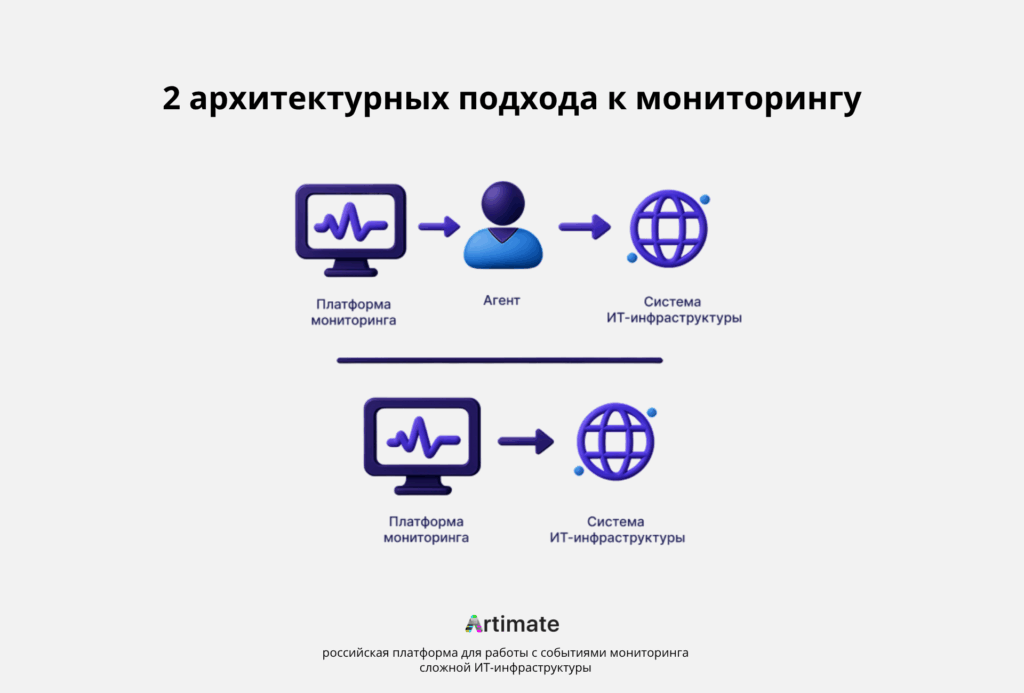
Мониторинг на основе агентов
Мониторинг на основе агентов предполагает установку программного агента на каждую систему, которую необходимо контролировать. Агент собирает данные с системы и отправляет их на сервер мониторинга. Например, это могут быть все запросы к приложению, службе или узлу.
Безагентный мониторинг
Безагентный мониторинг не требует установки программных агентов. Вместо этого он использует такие протоколы, как SSH, SNMP и WMI, для сбора и передачи данных из систем через открытые удаленные API.
Преимущества системы мониторинга IT-инфраструктуры

Предотвращение сбоев
Мониторинг выступает как система раннего предупреждения: еще до того, как деградация производительности превращается в инцидент, алерты сообщают о росте задержек, переполнении очередей сообщений или критически высокой температуре процессоров. Оперативная реакция позволяет локализовать проблему на стадии «симптомов» и тем самым избежать внеплановых простоев, потери транзакций и репутационных рисков.
Снижение затрат
Данные о фактической нагрузке помогают точнее планировать емкость — компания перестает закупать «железо про запас» или переоценивать объёмы облачных ресурсов. Дополнительно сокращаются расходы на экстренное восстановление инфраструктуры: профилактическая замена диска, выявленного мониторингом по SMART‑ошибкам, обходится гораздо дешевле, чем восстановление после аварийного выхода из строя.
Повышение безопасности
Наблюдаемость охватывает логи и сетевой трафик, фиксируя нетипичные попытки доступа, всплески аутентификационных ошибок или подозрительные шаблоны команд. Мониторинг интегрируется с SIEM/UEBA, автоматически обогащает события контекстом, а при необходимости изолирует уязвимый узел до вмешательства SOC‑команды. В результате снижается время обнаружения и нейтрализации кибератак.
Улучшение качества обслуживания клиентов
Метрики прикладного уровня (latency операций, процент ошибок, p95‑время отклика) напрямую коррелируют с пользовательским опытом. Когда SRE‑команда видит рост времени ответа API и оперативно масштабирует поды Kubernetes, клиенты зачастую даже не замечают потенциального сбоя. Стабильность сервисов повышает удовлетворенность и лояльность аудитории, а значит — удержание клиентов и доход.
Повышение уровня контроля
Централизованная панель мониторинга объединяет все данные: от температуры в стойках до бизнес‑транзакций. Руководители получают прозрачные дашборды по SLA, бюджету на инфраструктуру и эффективности изменений, инженеры — детальные графики для root‑cause‑анализа, а аудиторы — неизменяемый журнал событий. Такая сквозная контролируемость трансформирует ИТ из «черного ящика» в управляемый и предсказуемый актив бизнеса.
Компоненты систем мониторинга ИТ-инфраструктуры

Аппаратное обеспечение
Сердцем любой системы мониторинга остаётся физическая платформа: серверы, на которых работает ядро, и высокопроизводительная система хранения данных с отметками времени. Серверы отвечают за прием метрик, выполнение правил корреляции и генерацию алертов, а СХД обеспечивает быструю запись и выборку миллионов точек в секунду. При нагрузках enterprise‑уровня используют кластер из нескольких узлов с распределенным хранилищем (например, Ceph или SAN‑массив) и аппаратным резервированием питания, чтобы исключить единичные точки отказа.
Агенты мониторинга
На контролируемых хостах развертываются агенты — это могут быть программные агенты, контейнеры‑sidecar в Kubernetes или, реже, встроенные в оборудование аппаратные датчики IPMI, поддерживающие SNMP. Агенты собирают метрики ОС и приложений, выполняют чтение журналов журналы, выполняют запросы к сервисам и передают данные в ядро. Благодаря локальному кэшированию агенты продолжают писать телеметрию даже при потере связи с сервером и отправляют набор данных после восстановления канала.
Ядро системы и подсистемы анализа
На серверном уровне работает комплекс модулей: приемник данных, очередь сообщений, база база данных временных рядов, движок корреляции и алертинга, а также сервис прогнозной аналитики. Ядро построено на наборах библиотек и фреймворков: от gRPC‑шлюзов до модулей машинного обучения, интегрирующихся через Python или Go‑SDK. Подсистема обработки нормализует данные, устраняет дубликаты, вычисляет агрегаты (p95 latency, delta CPU) и применяет правила аномалий, после чего передает результаты в алерт‑менеджер и API для внешних систем (ServiceNow, Slack, SIEM).
Клиентский веб‑портал
Это удобный единый интерфейс, через который с системой работают разные роли. Инженер SRE в реальном времени отслеживает графики и логи, СТО просматривает сводные панели по SLA и затратам, а бизнес‑аналитик анализирует связь между ошибками и конверсией. Портал основан на микросервисной архитектуре, поддерживает гибкую настройку дашбордов методом «перетащи‑и‑положи», умеет формировать отчеты как по расписанию, так и по запросу. Здесь же администратор задает интеграции, правила оповещений и права доступа по RBAC. Мобильная версия присылает алерты и позволяет подтверждать их одним нажатием, что удобно для дежурных инженеров, работающих круглосуточно и не привязанных к рабочему месту.
Популярные системы для мониторинга ИТ-инфраструктуры
Система мониторинга Zabbix
Zabbix давно считается «универсальным солдатом» классического мониторинга. Это полностью открытое решение, которое устанавливается on‑prem и использует гибридную модель сбора: агенты на хостах, SNMP‑опрос оборудования, IPMI для аппаратных датчиков и Trapper‑режим для приема push‑метрик от внешних сервисов. Администратор получает готовые шаблоны для сетевых устройств, виртуализации, баз данных и популярных приложений, настраивает триггеры с несколькими уровнями серьёзности, а авто‑дискавери упрощает подключение сотен новых узлов. Под нагрузкой десятков тысяч элементов данных Zabbix требует грамотного тюнинга базы и сегментации прокси‑нод, зато остаётся одним из самых гибких и экономичных решений, полностью контролируемых внутри периметра компании.
Система мониторинга Prometheus
Prometheus вырос из экосистемы Cloud‑Native и ориентирован на микросервисные и контейнерные среды. Сервер Prometheus сам опрашивает экспортёры по pull‑модели и хранит метрики в собственную TSDB, что упрощает горизонтальное масштабирование. Язык запросов PromQL позволяет строить сложные агрегаты (rate, histogram_quantile, p99 latency) буквально в одну строку, а Alertmanager маршрутизирует уведомления в Slack, PagerDuty или собственные вебхуки. Для долгосрочного хранения и федерации крупных инсталляций используют надстройки Thanos или Cortex, которые превращают несколько кластеров Prometheus в единое логическое хранилище с ретеншном в годы. В результате этот стек стал де‑факто стандартом для Kubernetes‑платформ и DevOps‑команд, которым важна скорость развертывания и гибкость запросов.
Система мониторинга Nagios
Nagios остается своеобразным «старожилом» рынка. Вариант Core распространяется бесплатно и строится вокруг богатой экосистемы плагинов, написанных сообществом; коммерческая версия XI добавляет веб‑консоль, отчёты и мастера конфигурации. Nagios хорошо справляется с мониторингом сетевых сервисов (HTTP, SMTP, FTP), умеет работать по агентской и безагентной схемам и отличается скрупулезной проверкой «живости» процессов. Ограничения связаны в первую очередь с масштабируемостью и современным UX: при росте парка серверов до тысяч узлов конфигурационные файлы становится сложно поддерживать, а дашборды требуют доработок или интеграции с Grafana.
Российская система мониторинга wiSLA
ПАК wiSLA — российская платформа комплексного мониторинга и аналитики, предназначенная для контроля ИТ-инфраструктуры, каналов связи и бизнес-приложений в режиме 24/7. Платформа сочетает гибкость и масштабируемость, поддерживая как локальные, так и облачные конфигурации. wiSLA — единственное решение в России, имеющее статус утвержденного типа средства измерений. Единый интерфейс с настраиваемыми дашбордами и виджетами обеспечивает прозрачность и оперативный контроль всех объектов мониторинга, а техническая поддержка обеспечивает надежную и эффективную эксплуатацию.
Российская система мониторинга Пульт
«Пульт» — это российская система мониторинга ИТ-инфраструктуры, основанная на популярной открытой программной платформе Zabbix и дополненная новым удобным функционалом. Решение имеет расширенные интеграции, набор уникальных шаблонов мониторинга, выделенный модуль отчетности, работающий независимо от реализованного в Zabbix функционала, а также улучшенную производительность специально для инсталляций уровня enterprise. Внедрение системы «Пульт» позволяет организовать комплексный контроль за работой ИТ-инфраструктуры и бесшовно перейти с ранее используемых систем на российское решение с расширенной технической поддержкой.
Искусственный интеллект и машинное обучение в ИТ-мониторинге: проактивный подход к мониторингу ИТ сервисов
Сегодня большинству команд приходится жонглировать локальными дата‑центрами, частными и публичными облаками. Добавьте IaaS, PaaS, инфраструктуру как код и целый зоопарк поставщиков и платформ — и получите слишком много движущихся частей при катастрофической нехватке времени. 86 % предприятий называют гибридную модель «золотым стандартом» эксплуатации: она гибка, но приносит с собой дополнительную сложность.
Эта сложность бьет по повседневным операциям. Команды сталкиваются с:
- Усталостью от оповещений, когда системы мониторинга перегружены алертами;
- Большим количеством инцидентов, когда за ложными срабатываниями часто не видны реальные проблемы;
- Разрозненными инструментами, которые тормозят время реакции.
AIOps — это подход, который объединяет искусственный интеллект, машинное обучение и автоматизацию для управления IT-операциями. Он позволяет анализировать огромные объемы данных в реальном времени, выявлять закономерности, предсказывать потенциальные проблемы и автоматически принимать меры для их предотвращения.

Одна из ключевых функций AIOps — обработка данных из множества источников, включая логи, метрики производительности, информацию о сети и даже внешние данные, такие как погодные условия или рыночные тренды. Используя машинное обучение, AIOps выделяет аномалии и определяет их корневые причины.
БОЛЕЕ ПОДРОБНО ПРО AIOPS ЧИТАЙТЕ В НАШЕЙ СТАТЬЕ “Реактивный подход vs. AIOps: почему пора меняться?”
Вот несколько причин, по которым компании выбирают AIOps-решения:
- Автоматизация обнаружения и диагностики проблем ускоряет их устранение и снижает время простоя;
- Аналитика на основе данных помогает принимать обоснованные решения о распределении ресурсов и оптимизации производительности;
- Прогнозирование и предотвращение сбоев: система выявляет закономерности и устраняет проблемы до того, как они станут критичными;
- Предиктивный анализ позволяет заранее оценивать будущие тренды и потенциальные риски;
- Быстрый поиск первопричин: AIOps анализирует данные из разных приложений и систем, значительно сокращая время, затрачиваемое на ручной поиск источника проблемы.
При грамотном использовании AIOps превращается в систему раннего предупреждения. Он не заменяет наблюдаемость, а опирается на нее: превращает сырые данные в контекст, а алерты — в действия. В итоге компания формирует по‑настоящему проактивную ИТ‑службу, стабильно повышает качество клиентских сервисов и надежно подводит технологическую основу под долгосрочные цели бизнеса.
Российская AIOps-платформа Artimate для ИТ-мониторинга

Artimate — российская аналитическая AIOps-платформа для работы с событиями мониторинга сложной ИТ-инфраструктуры. Платформа использует технологии искусственного интеллекта и машинного обучения, чтобы отфильтровать лишние оповещения и выделить только действительно важные инциденты. Artimate автоматически коррелирует события из разных систем, обогащает их полезным контекстом, определяет первопричины и выдает рекомендации, снижая нагрузку на персонал и обеспечивая стабильную работу критичных бизнес-сервисов.
Платформа Artimate позволяет:
- сократить информационный шум на 95 %;
- удерживать доступность сервисов на уровне 99,9999 % SLA;
- выполнять корреляцию событий и анализ первопричин;
- прогнозировать сбои и устранять их проактивно;
- автоматизировать реагирование и принятие решений;
- интегрироваться с популярными системами мониторинга.
Хотите увидеть, как это работает на практике? Попробуйте Artimate уже сейчас и убедитесь сами, как машинное обучение и ИИ делают мониторинг быстрее, умнее и эффективнее!
