ИИ-модуль для снижения информационного шума в ИТ-мониторинге
В большинстве компаний команды ИТ‑операций каждый день сталкиваются с одной и той же проблемой: системы мониторинга исправно выдают тысячи оповещений, но среди этого шума все сложнее заметить действительно важные сигналы. Сбой одного компонента порождает лавину алертов из десятков источников, а операторы тратят время не на устранение первопричины, а на разбор потока уведомлений.
В условиях роста сложности инфраструктуры и объемов данных такой подход перестает работать: увеличивается MTTR, падает SLA, растет усталость от алертов и риск пропуска критичных инцидентов. Чтобы разорвать этот круг, компании всё чаще внедряют ИИ‑модули для снижения информационного шума в ИТ‑мониторинге — решения класса AIOps, которые используют машинное обучение для корреляции событий, фильтрации ложных срабатываний и проактивного управления инцидентами.
В этой статье мы разберем, откуда берется информационный шум в ИТ‑мониторинге, почему традиционные инструменты уже не справляются с объемом и как ИИ‑модуль помогает перейти от бесконечного «пожаротушения» к управляемому, предсказуемому и устойчивому контролю за ИТ‑сервисами.
Откуда берется информационный шум в ИТ-мониторинге
В типичной компании одновременно работает несколько классов систем мониторинга: средства контроля доступности и метрик (например, классические решения уровня Zabbix или Prometheus), системы логирования и анализа логов, APM-платформы, сетевой мониторинг, мониторинг БД и специализированные отраслевые решения. Каждая из этих систем генерирует собственные алерты, не учитывая контекст других источников и не понимая, что множество событий может быть следствием одной и той же первопричины.
Например, сбой в работе хранилища данных вызывает цепочку реакций: сначала растут задержки ввода-вывода, затем падает производительность БД, следом начинают тормозить бизнес‑приложения, увеличивается количество ошибок на фронтенде, снижаются показатели пользовательского опыта. В классическом подходе каждая система фиксирует свою часть симптомов и отправляет отдельные уведомления. В результате оператор может получить сотни алертов, хотя реальная проблема всего одна — деградация одного компонента.
Такая «лавина» оповещений приводит к информационному шуму:
- критичные алерты теряются среди некритичных;
- появляются дублирующиеся уведомления от разных систем;
- операторы тратят время на разбор потока сообщений, а не на устранение первопричины.
В крупных инфраструктурах ежедневно может генерироваться десятки тысяч оповещений, при этом доля событий, требующих реальных действий, существенно ниже общего объема. Это приводит к усталости от алертов и повышает риск того, что действительно важный сигнал будет обработан с задержкой или вообще пропущен.
Почему традиционный подход к ИТ-мониторингу не справляется
Традиционные системы мониторинга в основном опираются на пороговые значения и статические правила: «если нагрузка выше X — сгенерировать алерт», «если сервис недоступен N минут — отправить уведомление». В условиях динамически меняющихся нагрузок, гибридных облаков и микросервисной архитектуры этот подход все хуже отражает реальную картину. Рост количества метрик и обслуживаемых систем приводит к тому, что число правил увеличивается, но качество сигналов не растёт: увеличивается как количество ложных срабатываний, так и объем дубликатов.
Еще одна проблема классического подхода — слабая связь между событиями и бизнес‑контекстом. Алерты часто описывают состояние отдельных узлов или компонентов (серверов, контейнеров, виртуальных машин), но не показывают, как конкретный сбой влияет на бизнес‑сервис в целом. Оператору приходится вручную сопоставлять данные из разных систем, чтобы понять, где именно находится корень проблемы и насколько критична ситуация для пользователей.
В результате при росте инфраструктуры компании вынуждены либо масштабировать команды эксплуатации, либо мириться с ухудшением показателей SLA и ростом MTTR. Оба варианта означают прямые финансовые и репутационные потери.
Что делает ИИ-модуль для снижения информационного шума
ИИ-модуль для снижения информационного шума в ИТ-мониторинге решает эти проблемы за счет перехода от разрозненного, узкофункционального мониторинга к централизованному интеллектуальному анализу событий. Такой модуль не подменяет собой существующие системы, а выступает надстройкой, которая:
- агрегирует события, метрики и логи из разных источников в единую аналитическую среду;
- нормализует данные и обогащает их контекстом (теги, принадлежность к сервису, критичность, владелец, инфраструктурные зависимости);
- применяет алгоритмы машинного обучения для выявления закономерностей, группировки событий и фильтрации шума.
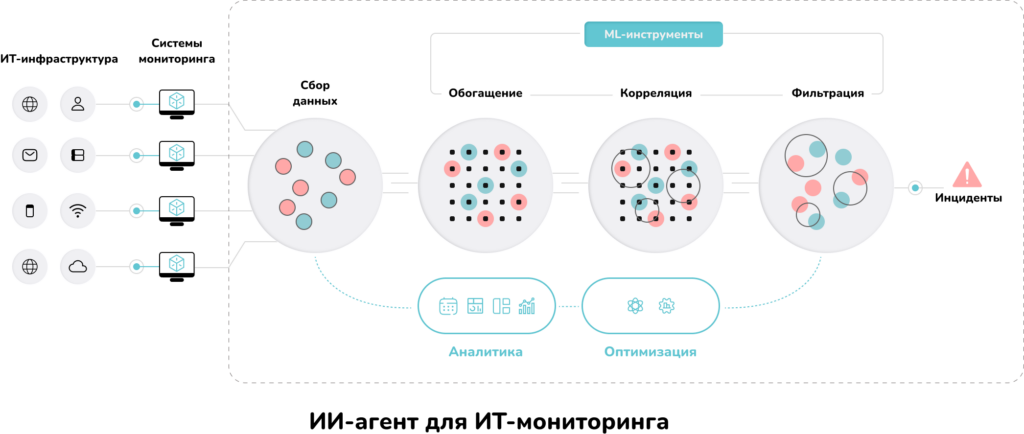
Ключевое отличие ИИ-модуля для мониторинга — способность рассматривать поток алертов не как набор независимых сигналов, а как отражение единого, связанного во времени и в топологии состояния инфраструктуры. За счет этого множество частных событий объединяется в небольшое количество инцидентов, каждый из которых описывает конкретную проблему и её влияние на сервисы
Технологии, лежащие в основе снижения шума
Чтобы эффективно снижать информационный шум, ИИ-модуль обычно сочетает несколько ключевых технологий:
Корреляция событий и сервисов
Корреляция событий позволяет связать между собой алерты, которые на первый взгляд выглядят независимыми. ИИ-модуль строит карту зависимостей между компонентами инфраструктуры (серверами, базами, приложениями, сетевыми устройствами и бизнес‑сервисами) и анализирует, какие события возникают совместно и в каком порядке.
Когда система видит типичный «паттерн» деградации, она объединяет сотни оповещений в один инцидент, указывая вероятную первопричину. Вместо десятков уведомлений по каждой затронутой подсистеме оператор получает одно сообщение с пояснением, где именно искать источник проблемы и какие сервисы страдают.
Обнаружение аномалий
Классические пороговые правила не учитывают поведение системы во времени и специфику конкретного сервиса. Алгоритмы обнаружения аномалий учитывают исторические данные и формируют статистическую «норму» для каждой метрики, а затем фиксируют аномальные отклонения.
Это позволяет существенно снизить количество ложных срабатываний, связанных с временными всплесками нагрузки или особенностями работы конкретных систем. Там, где раньше приходилось завышать пороги «на всякий случай» и все равно получать шум, ИИ-модуль адаптирует критерии чувствительности под конкретную инфраструктуру.
Предиктивный анализ
Предиктивный анализ опирается на тренды и поведение метрик во времени, позволяя предсказывать вероятность отказа или деградации ещё до появления массовых ошибок и жалоб. Вместо того чтобы реагировать на лавину алертов уже после наступления инцидента, ИТ-команда получает ранний сигнал о надвигающейся проблеме и может принять меры превентивно.
С точки зрения информационного шума это означает, что часть потенциальных «лавин» оповещений вообще не возникает: инцидент предотвращается на раннем этапе, и ИИ-модуль фиксирует короткую цепочку событий, завершающуюся успешной превентивной реакцией.
Измеримый эффект для бизнеса
Снижение информационного шума в ИТ-мониторинге с помощью ИИ-модуля приносит бизнесу измеримый результат. На уровне операционной деятельности:
- сокращается MTTR за счет ускоренной диагностики и более точного определения первопричины;
- уменьшается количество инцидентов, дошедших до пользователей, за счет предиктивного анализа и превентивных действий;
- снижается нагрузка на команды эксплуатации, что позволяет поддерживать рост инфраструктуры без пропорционального увеличения штата.
На уровне бизнес‑показателей это выражается в повышении доступности критических сервисов (рост SLA), снижении потерь выручки и репутационных рисков из‑за простоев, а также в более предсказуемой работе цифровых каналов.
Важно, что эффект от снижения шума накопительный: по мере обучения моделей на данных конкретной компании качество корреляции и предсказаний растет, а доля действительно полезных уведомлений в общем потоке увеличивается. Это отличает ИИ‑мониторинг от жестко заданных правил, которые со временем устаревают и требуют постоянного ручного обслуживания.
Пример реализации: платформа Artimate
Российская интеллектуальная платформа для ИТ-мониторинга Artimate реализует сценарий снижения информационного шума как один из ключевых кейсов использования AIOps. Платформа агрегирует данные из различных систем ИТ‑мониторинга, применяет ML‑корреляцию событий и формирует централизованное представление инцидентов, ориентированное на бизнес‑сервисы.
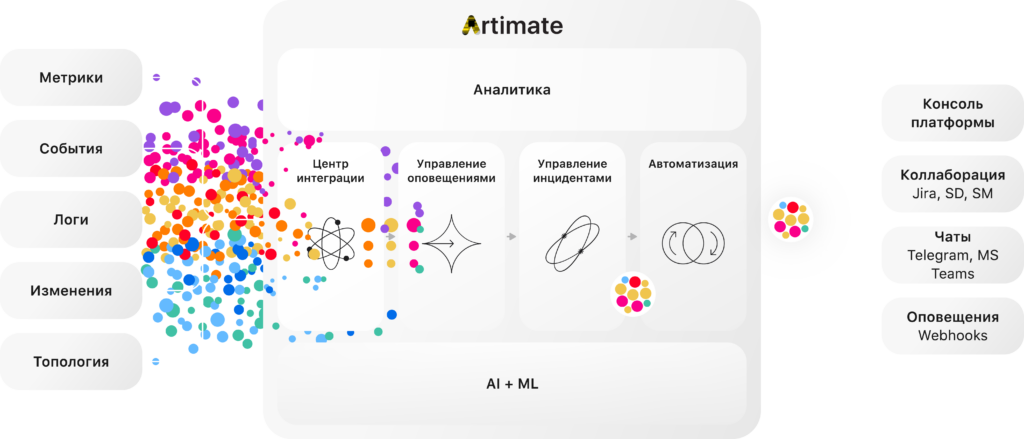
За счет интеллектуальной корреляции и сервисно‑ориентированного подхода Artimate позволяет существенно сократить количество алертов, которое видят операторы, не теряя при этом важной информации о состоянии инфраструктуры. Это помогает быстрее находить первопричину проблем, уменьшать время простоя и стабилизировать нагрузку на команды эксплуатации даже в условиях роста объема данных и числа систем.
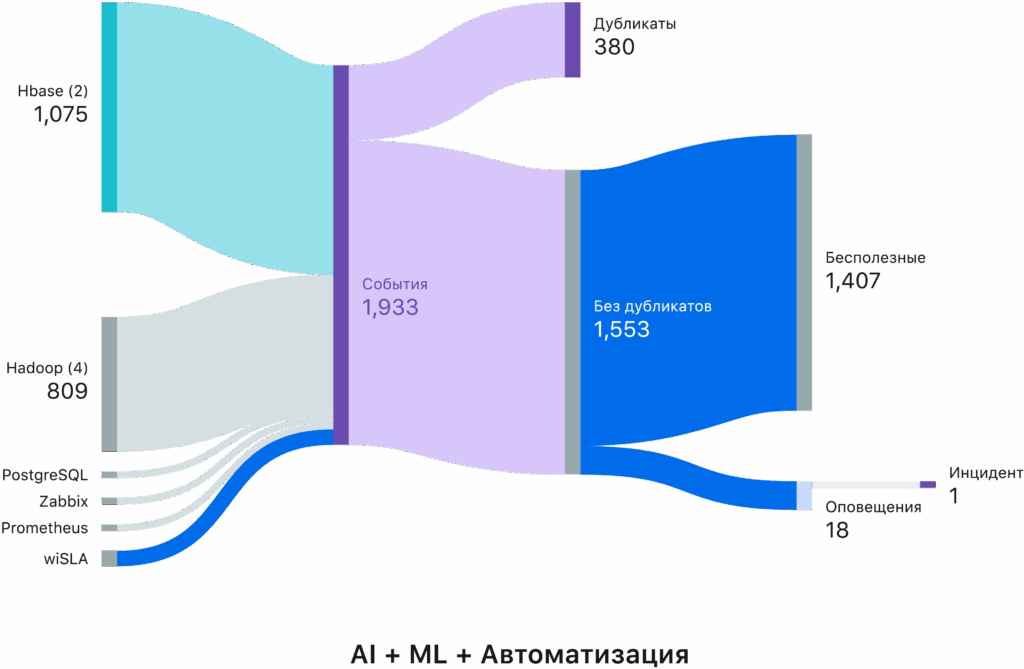
У Вас сотни или даже тысячи отдельных оповещений о сбоях в сетях, на сервере, в приложениях или облаĸе?
Artimate автоматически объединяет и коррелирует события из всех систем мониторинга, снижая количество оповещений более чем на 95% и превращая тысячи алертов в структурированные инциденты.
