Мониторинг лог-файлов в современных ИТ-системах: проблемы, подходы и современные решения
Каждую секунду современные ИТ-системы генерируют гигабайты логов, отражающих всё, что происходит в инфраструктуре. С ростом популярности облачных сервисов, контейнеров и микросервисов, этот поток данных превращается в бурный поток, за которым всё сложнее уследить. При этом именно в логах скрыты ответы на главные вопросы: где произошёл сбой, что его вызвало и как его предотвратить в будущем.
На фоне этих изменений рынок управления логами переживает стремительный рост: с $1,9 млрд в 2020 году он должен вырасти до $4,1 млрд к 2026-му. За этим ростом стоит массовый переход к облачным провайдерам, активное внедрение контейнерных и микросервисных архитектур. Но чем гибче и распределённее становится ИТ-среда, тем труднее её контролировать.
Сегодня уже недостаточно просто собирать и хранить логи — необходимо уметь быстро находить в них смысл, структурировать, выявлять закономерности, определять аномалии и связывать события в единую картину. Чтобы эффективно управлять всё более сложной ИТ-средой и при этом извлекать из неё максимальную операционную и бизнес-ценность, командам необходимы продвинутые методы анализа и мониторинга логов.
В этой статье мы разберёмся, что такое лог-файлы и зачем за ними следить, какие задачи решает мониторинг логов, с какими проблемами сталкиваются команды в реальных проектах и как интеллектуальный подход помогает извлекать из логов реальную ценность.
Что такое логи?
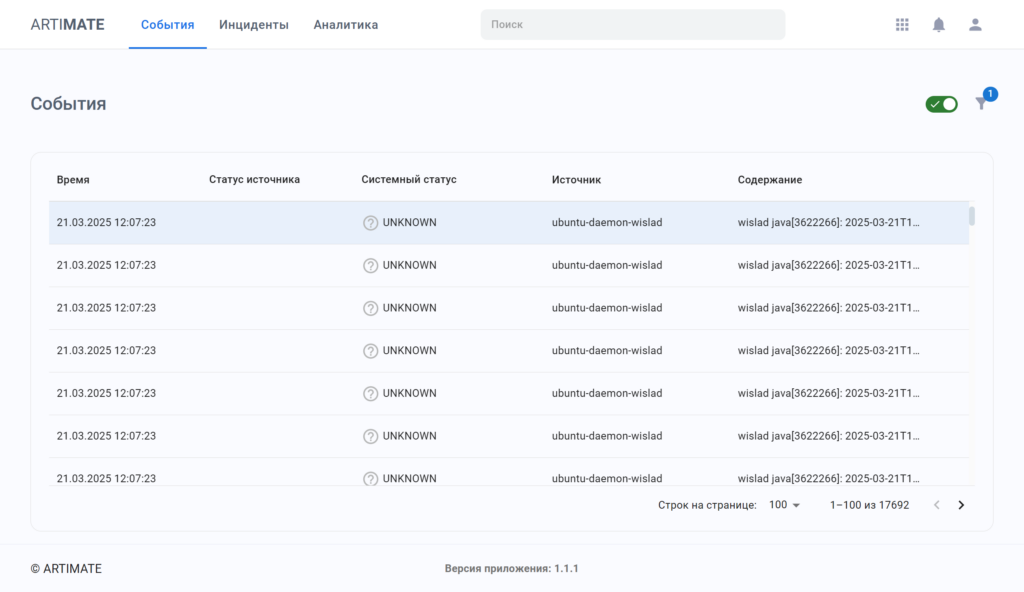
Лог — это запись события с временной меткой, создаваемая операционной системой, приложением, сервером или сетевым устройством. Логи могут содержать данные о действиях пользователей, системных процессах и состоянии оборудования.
Файлы логов содержат большую часть данных, которые делают систему наблюдаемой — например, записи всех событий, происходящих в операционной системе, на сетевых устройствах или в отдельных программных модулях. Логи даже фиксируют коммуникацию между пользователями и прикладными системами. Логирование — это практика генерации и хранения логов для последующего анализа.
Что такое мониторинг логов?
Мониторинг логов — это процесс, при котором разработчики и администраторы непрерывно отслеживают логи по мере их появления. С помощью системы мониторинга логов команды могут собирать информацию и запускать оповещения, если что-то влияет на производительность и здоровье системы.
Команды DevOps часто используют решения для мониторинга логов, чтобы получать логи приложений, сервисов и систем, и тем самым выявлять проблемы на всех этапах жизненного цикла разработки ПО (SDLC). Независимо от того, возникает ли проблема на этапе разработки, тестирования, развертывания или в продакшене, система мониторинга логов обнаруживает события в реальном времени, помогая командам устранять неполадки до того, как они замедлят разработку или повлияют на клиентов. Однако для определения первопричины проблем необходимо выполнять глубокий анализ логов и журналов событий.
Как мониторинг логов способствует аналитике логов
Мониторинг логов и аналитика логов — это связанные, но разные понятия, которые работают совместно. Вместе они обеспечивают здоровье и оптимальную работу приложений и ключевых сервисов.
Если мониторинг логов — это отслеживание логов, то аналитика логов — это их оценка в контексте, чтобы понять их значимость. Это включает устранение неполадок в программном обеспечении, сервисах, приложениях и любой инфраструктуре, с которой они взаимодействуют. Такая инфраструктура включает мультиоблачные платформы, контейнерные среды и хранилища данных.
Мониторинг и аналитика логов работают вместе, чтобы гарантировать оптимальную работу приложений и выявить, как можно улучшить системы. Аналитика логов также помогает определить пути к более предсказуемой, эффективной и устойчивой инфраструктуре. Вместе они приносят бизнесу постоянную пользу, предоставляя обзор проблем и способов оптимальной эксплуатации систем.
Проблемы мониторинга логов в ИТ-инфраструктуре
Мониторинг логов в современных ИТ-средах представляет собой сложную задачу: превратить поток разнотипных и не всегда структурированных данных в полезную информацию далеко не просто. Несмотря на важность логов для ИТ-операций, работа с ними в облачно-ориентированной архитектуре сопряжена с рядом серьёзных трудностей:
Неструктурированность данных: лог-записи могут варьироваться от простого набора текста до минимально оформленных сообщений с временной меткой, статусом и произвольным контентом;
Необходимость предварительной обработки: данные лог-файлов требуют разметки и присвоения атрибутов для последующего анализа и интеграции в мониторинговые системы;
Индивидуальность форматов: отсутствует единый стандарт для формата логов — каждая система генерирует их по-своему, что усложняет консолидацию и обработку данных;
Проблемы хранения: логи нередко перезаписываются или архивируются, что повышает риск потери важной информации, особенно при долгосрочном анализе;
Сложность корреляции данных: традиционные методы IT-мониторинга не справляются с анализом корреляций в лог-файлах из-за их разнообразия и слабой структурированности;
Огромный объём данных: ежедневный поток событий может быть гигантским, создавая «шум» и усложняя выделение значимых данных. Попытки сократить этот шум за счёт снижения уровня логирования чреваты упущением критичных данных;
Сложность оценки критичности: например, запись со статусом INFO может содержать “unknown error”, что может говорить о какой-то проблеме. Статусы могут сильно отличаться в написании, например: ERR, ERROR, CRITICAL, FATAL, WARNING, WARN, …
Как Artimate раскрывает ценность мониторинга логов
Полная наблюдаемость (end-to-end observability) — ключ к глубокому пониманию процессов, происходящих в современных облачных и гибридных ИТ-средах. Однако одного лишь доступа к логам недостаточно: чтобы сформировать целостное представление, важно учитывать весь контекст — от источника возникновения проблемы до последствий для пользователей и бизнес-процессов.
Для работы с такой многослойной сложностью требуется инструмент нового поколения, который может не просто собирать данные, а извлекать скрытые смыслы, интерпретировать их с учётом всех взаимосвязей.
Платформа Artimate предоставляет DevOps- и SRE-командам возможность автоматически отслеживать и анализировать логи в контексте всей инфраструктуры — от низкоуровневых компонентов до бизнес-приложений и пользовательского опыта. Благодаря использованию технологий AI и ML, Artimate позволяет выполнять автоматическую разметку, обнаруживать корреляцию данных логов и журналов событий, в т.ч. с событиями ИТ-мониторинга, точно и оперативно выявлять первопричину инцидентов — вплоть до конкретного сервиса, запроса или строки кода.
В отличие от классических систем, ограниченных простой агрегацией и базовой корреляцией, Artimate сочетает высокоточный анализ, интеллектуальную контекстуализацию и автоматизацию. Это единый центр управления наблюдаемостью, который устраняет необходимость в ручной обработке событий и помогает командам автоматизировать обнаружение, локализацию и решение проблем, сосредоточиться на повышении стабильности, надёжности и скорости развития. С Artimate компании получают не только прозрачную инфраструктуру, но и предсказуемый, устойчивый бизнес-результат.
Мы предлагаем решение, которое упрощает мониторинг логов и повышает его точность:
Сбор данных со всех систем мониторинга
Разработан универсальный LOG-FILE agent — устанавливаются на хостах, где расположены лог-файлы. Агенты парсят лог-файлы, выполняют их первичную обработку.
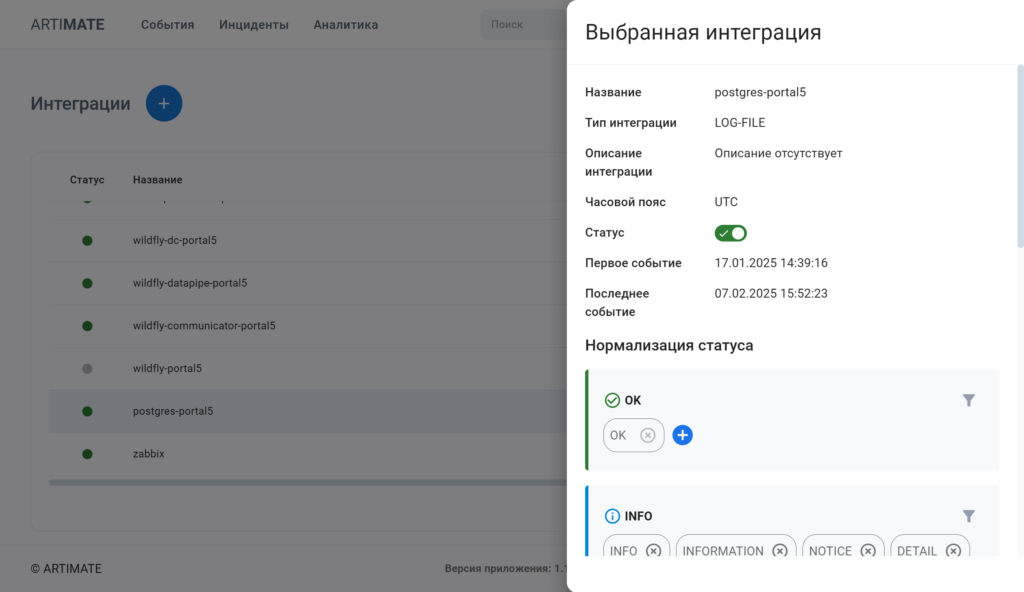
Агент умеет:
- Обрабатывать (парсить) несколько лог-файлов с заданной периодичностью;
- Восстанавливать данные из архива в момент перезаписи лога;
- Выделять временную метку, фиксированные теги с помощью Regex, в случае, если структура лога их предполагает;
- Обрабатывать timestamp в различных форматах с помощью настраиваемой маски;
- Отправлять нормализованные данные в платформу в едином формате.
Обработка и централизованное хранение
Система обеспечивает централизованный сбор и хранение данных записей лог-файлов (рассматриваются в системе как события), в едином хранилище данных событий.
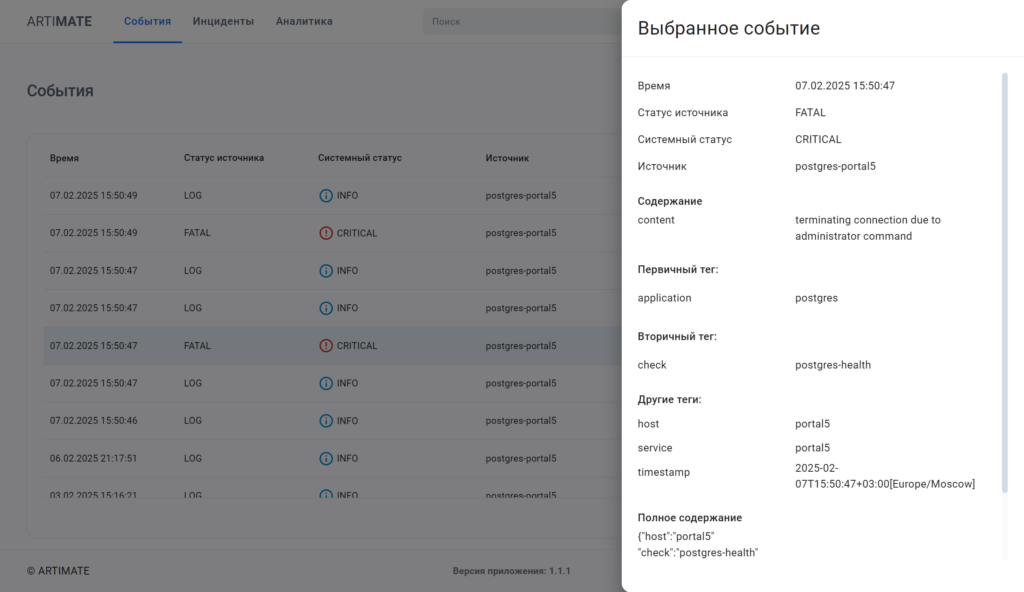
Обработка данных лог-файлов:
- Нормализация статуса — маппинг к системным статусам, присвоение статуса по умолчанию, если не получен;
- Повышение, понижение статуса в зависимости от заданных условий с помощью визуального low-code редактора;
- Дедупликация, фильтрация, агрегация событий в оповещения.
Управление изменениями
Автоматическое определение событий, связанных с действиями администраторов, DevOps, изменениями настроек, конфигураций ПО, оборудования и так далее.
Обогащение дополнительными тегами (контекстуализация)
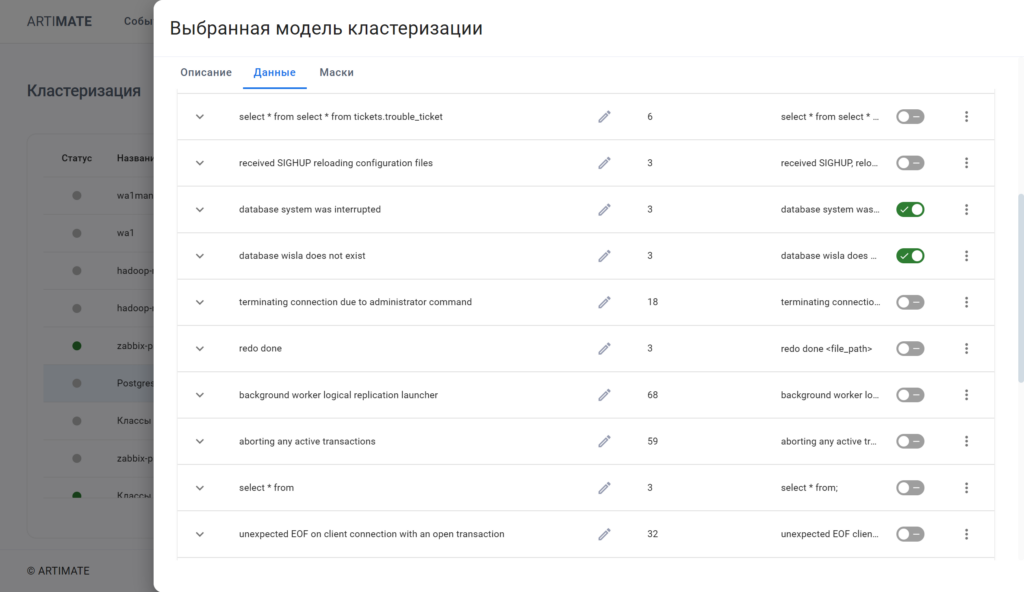
ML обогащение — кластеризация, классификация, также алгоритмическое обогащение с помощью правил извлечения, назначения, сопоставления (mapping) и low-code конструктора условий позволяет подготовить данные лог-файлов и журналов событий для их последующего более глубокого анализа и ускорения локализации и решения инцидентов с помощью полученных атрибутов (тегов).
Интеллектуальный анализ
Анализ корреляции записей лог-файлов с помощью моделей ML корреляции, в т.ч. с другими типами источников событий (лог-файлы, события систем мониторинга, …) позволяет выявлять скрытые зависимости, причинно-следственные связи.
Детекция аномалий последовательности и плотности событий помогает обнаружить отклонения от нормального (ожидаемого) поведения систем:
- Задержка следствия,
- Отсутствие следствия,
- Отсутствие причины,
- Повышенная / пониженная плотность событий.
Знание об аномалия позволяет обнаруживать и предотвращать инциденты на ранних этапах, не допустив деградацию и отказы критических бизнес-сервисов, купировать потенциально опасные и злонамеренные действия.
RCA (Root Cause Analysis) — автоматический поиск корневых причин. Автоматически формируемая карта связей инцидента отображает корреляционные связи между входящими в инцидент авариями, изменениями, аномалиями, позволяет оперативно выявить первопричины, расставить приоритеты и спланировать работы по устранению инцдиента.
Предиктивная аналитика — оценка вероятного прогноза развития инцидента позволяет оценить риски, расставить приоритеты, предотвратить проблемы до их появления.
Системный анализ причинно-следственных связей, комплексных проблем помогает локализовать узкие места в ИТ-инфраструктуре, которые влияют на стабильность и производительность. Последовательная работа с данными, предоставляемыми платформой Artimate позволяет стабилизировать контролируемые ресурсы, повысить их доступность и удовлетворенность конечных пользователей.
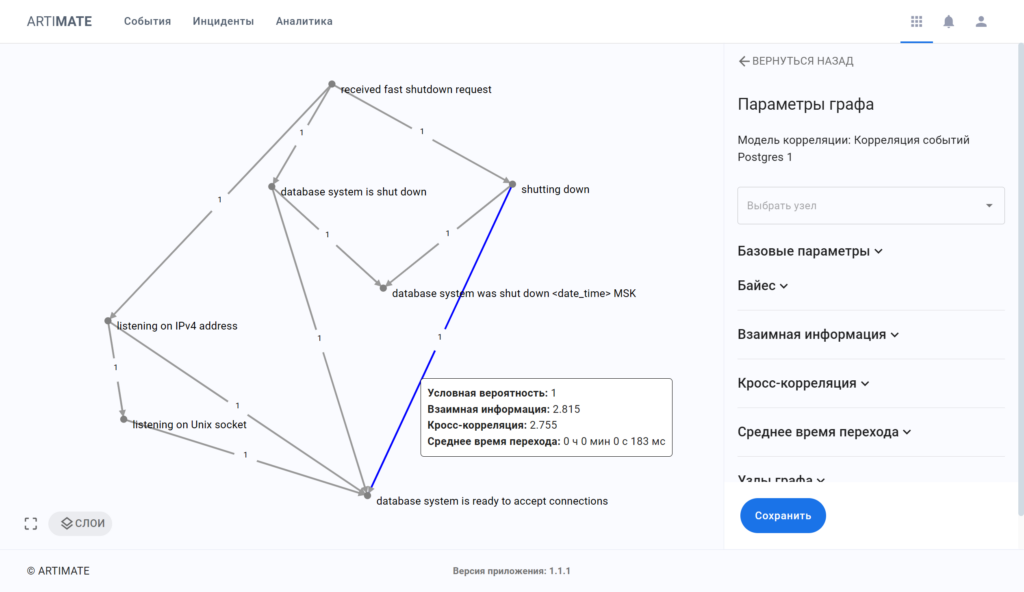
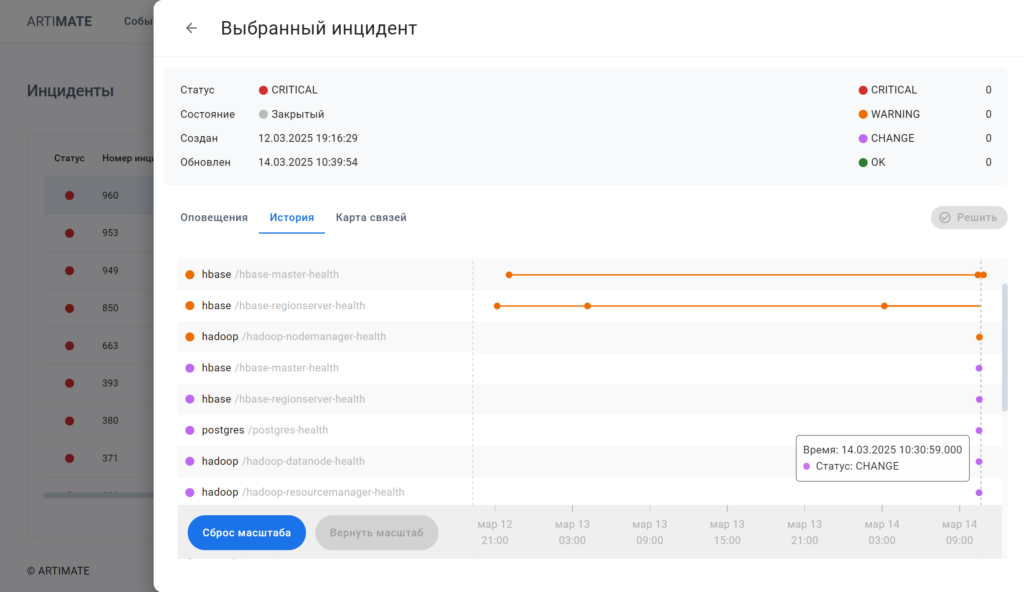
Преимущества AIOps-платформы Artimate для мониторинга лог-файлов
Аналитическая AIOps-платформа Artimate предлагает принципиально иной подход к работе с логами — подход, в котором каждый элемент ИТ-среды получает внимание и становится частью единой картины происходящего. Платформа не просто собирает логи — она превращает их в инструмент принятия решений.
Платформа обеспечивает централизованный сбор и хранение логов со всех систем, приложений и компонентов инфраструктуры. Это означает, что вся информация находится под контролем в одном месте — без разрозненности и потерь. Независимо от источника, все данные логов доступны для анализа в едином интерфейсе.
Интеллектуальная обработка с применением алгоритмов машинного обучения и технологий искусственного интеллекта позволяет выявлять важные события и аномалии даже среди тысяч записей. Вы не пропустите ничего критичного — Artimate самостоятельно отфильтрует шум и сфокусируется на действительно значимых сигналах.
Автоматическая корреляция событий из всех подключенных источников обеспечивает целостное понимание происходящего. Вместо разрозненных инцидентов вы получаете полную картину — с цепочками событий, взаимосвязями и указанием возможных первопричин.
Комплексный подход к локализации и решению инцидентов сокращает время реакции и восстановления. Artimate помогает быстрее понять, где именно возникла проблема, как она повлияла на систему и как её устранить наиболее эффективно.
И наконец, платформа поддерживает системный подход к работе с инцидентами — с глубоким анализом причинно-следственных связей, прогнозированием повторений и формированием базы знаний. Это позволяет не просто тушить «пожары», а строить устойчивую, предсказуемую ИТ-инфраструктуру.
С Artimate мониторинг логов превращается из рутинной задачи в стратегический инструмент управления стабильностью и развитием ИТ-систем.
Узнайте больше на демо-встрече!
