
Современные IT-инфраструктуры становятся всё сложнее, и управление ими требует новых подходов. Устаревшие методы, основанные на ручном анализе данных и реакции на инциденты постфактум, больше не соответствуют требованиям бизнеса. Здесь на помощь приходит инновационная технология AIOps.
AIOps не просто модернизирует мониторинг и управление IT-системами, но и позволяет компаниям переходить от реактивного подхода к проактивному, обеспечивая высокую стабильность, снижение затрат и улучшение качества обслуживания клиентов. В этой статье мы разберём, что такое AIOps, как он работает, его преимущества и основные сценарии применения.
Что такое AIOps?
AIOps, или Artificial Intelligence for IT Operations, представляет собой передовую методику управления IT-инфраструктурой с использованием технологий искусственного интеллекта.
Этот термин был введен в 2016 году компанией Gartner как сокращение от «Algorithmic IT Operations». AIOps стал логичным продолжением концепции IT Operations Analytics, отражая следующий этап эволюции управления IT-операциями. Этот подход сочетает в себе машинное обучение (ML), обработку естественного языка (NLP) и аналитику больших данных, чтобы обеспечить проактивный мониторинг, управление и оптимизацию IT-операций. AIOps помогает справляться с вызовами современных IT-систем, включая сложность данных, растущие операционные требования и необходимость повышения эффективности.
Как работает AIOps?
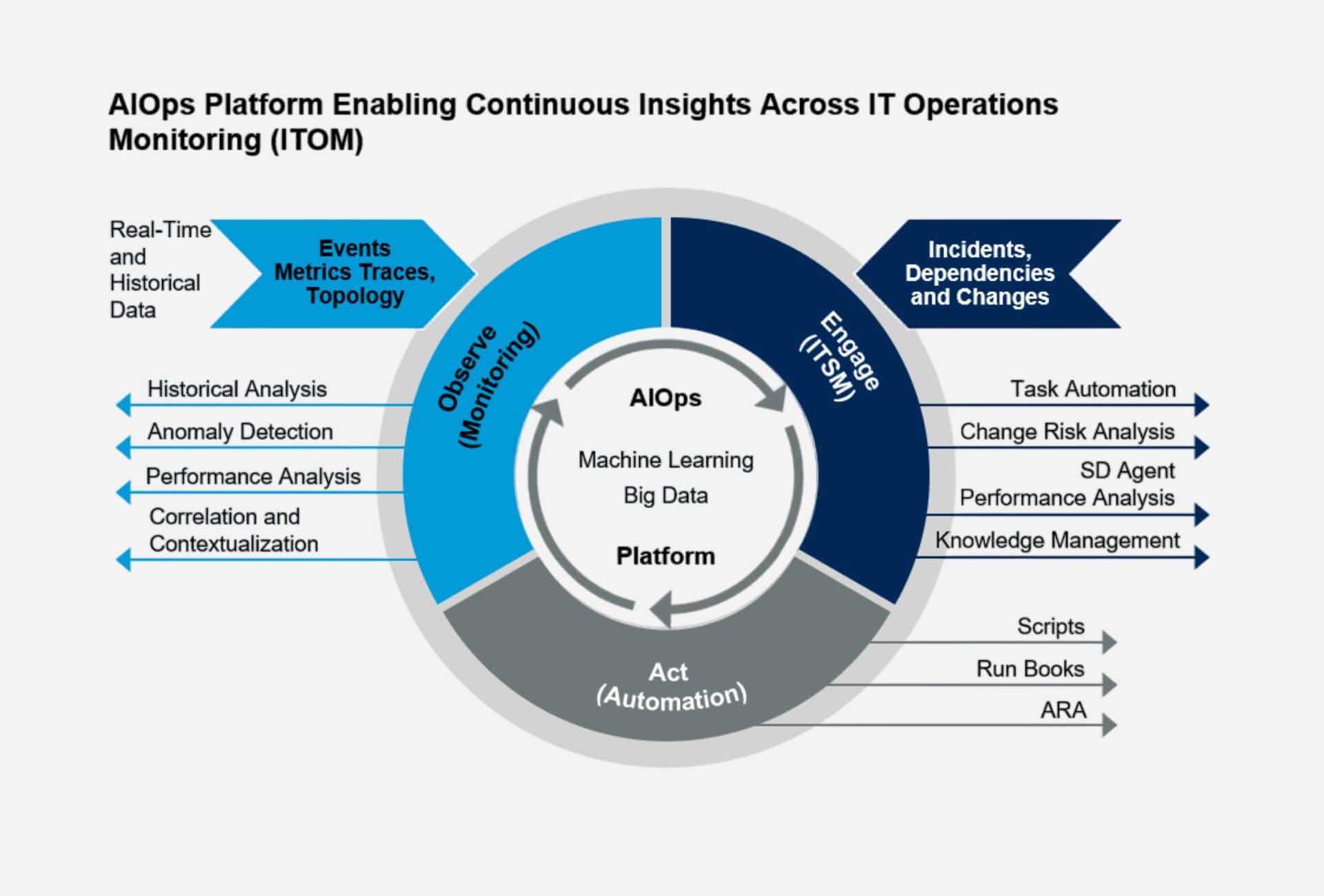
AIOps — это многоуровневая технология, которая объединяет сбор данных, анализ и автоматизацию, чтобы упростить управление IT-инфраструктурой и минимизировать человеческое вмешательство. Весь процесс работы AIOps можно представить в виде последовательности взаимосвязанных этапов, каждый из которых играет ключевую роль.
1. Сбор и агрегация данных
AIOps платформы объединяют данные из различных источников, включая журналы событий, log-файлы, показатели производительности, сетевые данные и пользовательские отчёты. Эти данные могут поступать в реальном времени или быть историческими, что позволяет анализировать текущую ситуацию и выявлять долгосрочные тренды.
2. Нормализация и обработка данных
После сбора информация очищается и структурируется для анализа. Этот процесс критически важен, так как «сырые» данные часто бывают хаотичными и неполными. Нормализация позволяет обеспечить высокую точность последующего анализа и делает данные удобными для обработки с помощью алгоритмов машинного обучения.
3. Анализ с помощью машинного обучения
Машинное обучение — основной двигатель AIOps. Системы используют алгоритмы для выявления аномалий, корреляции событий и прогнозирования возможных проблем. Например, платформа может обнаружить закономерности, которые указывают на приближающийся сбой оборудования. Машинное обучение позволяет AIOps выявлять глубинные взаимосвязи между событиями, которые не всегда очевидны для IT-специалистов.
4. Обнаружение аномалий и корреляция событий
Система сопоставляет события из разных источников и определяет, какие из них связаны между собой. Благодаря корреляции, IT-команды получают точную информацию о причинах проблемы и её последствиях, что значительно ускоряет устранение инцидента.
5. Автоматизация действий
AIOps не только анализирует данные, но и предлагает решения или автоматически запускает исправительные действия. Например, если система обнаруживает перегрузку сервера, она может автоматически распределить нагрузку или перезапустить определённые процессы.
Реактивный vs проактивный подход в ИТ- мониторинге
AIOps привносит множество преимуществ, которые выходят за рамки стандартного подхода к управлению ИТ. Чтобы понять его значимость, начнём с различия между традиционным реактивным и современным проактивным подходом в IT-мониторинге.
Реактивный подход: устаревшая модель
Реактивный подход — это традиционная модель, в которой команды реагируют на инциденты только после их возникновения. Например, если сервер выходит из строя, команда устраняет проблему, используя ручные процессы и анализ журналов.
Основные недостатки такого подхода:
- Длительное время обнаружения и устранения проблем. Проблема может оставаться незамеченной до тех пор, пока не повлияет на производительность или доступность сервисов.
- Увеличение рисков простоя и финансовых потерь. Каждая минута простоя может стоить компании значительных финансовых и репутационных потерь.
- Высокая нагрузка на ИТ-специалистов из-за частых повторяющихся задач. IT-специалисты вынуждены тратить ресурсы на одни и те же проблемы, вместо того чтобы фокусироваться на развитии и улучшении систем.
AIOps: переход к проактивному управлению
С внедрением AIOps организациям удаётся перейти к проактивному управлению. Это означает, что потенциальные проблемы выявляются и устраняются ещё до того, как они могут повлиять на бизнес-процессы.
AIOps анализирует данные из всех доступных источников: логи, метрики, сетевые события. На основе исторических данных и в реальном времени система выявляет аварии, аномалии, закономерности, оценивает прогноз и предупреждает возможные сбои. Например, система может обнаружить аномалию в поведении приложения на основе данных ИТ-мониторинга, log-файлов и предсказать ее влияние на работу кричного бизнес-сервиса.
Преимущества внедрения AIOps

Повышение операционной эффективности
AIOps берет на себя выполнение рутинных задач, таких как обработка заявок, настройка систем и анализ данных, освобождая IT-команды от однообразной работы и сокращая операционные затраты компаний в среднем на 30%. Вместо того чтобы тратить время на повторяющиеся процессы, специалисты могут сосредоточиться на стратегически важных направлениях: улучшении пользовательского опыта, разработке инновационных решений и модернизации IT-инфраструктуры.
Улучшенное управление инцидентами
AIOps сокращает время обнаружения и устранения инцидентов благодаря автоматическому анализу первопричин. Системы быстро сопоставляют данные из разных источников, выявляют корневые причины проблем и предлагают эффективные решения. Это позволяет уменьшить среднее время на устранение инцидента (MTTR) до 70%.
Проактивный подход
Проактивный подход AIOps позволяет заранее прогнозировать потенциальные сбои в инфраструктуре. Системы анализируют данные о работе оборудования и предсказывают его возможные неисправности, например, необходимость замены до поломки. Это снижает затраты на экстренные ремонты, продлевает срок службы IT-компонентов и уменьшает вероятность внезапных сбоев.
Повышение качества обслуживания клиентов
Когда инфраструктура работает стабильно и без сбоев, пользователи получают лучший опыт. Компании с внедрённым AIOps наблюдают увеличение уровня удовлетворённости клиентов на 25-30%, благодаря сокращению числа инцидентов и времени их устранения.
Сценарии использования AIOps
Сервисы AIOps предоставляют организациям мощные инструменты для решения ключевых задач в управлении IT-инфраструктурой, улучшении производительности и повышении безопасности. Рассмотрим основные сценарии их применения.
Анализ первопричин (Root Cause Analysis)
Анализ первопричин позволяет определить основную причину проблемы, чтобы устранить её с помощью соответствующих решений. Этот подход помогает командам избегать неэффективной работы по устранению симптомов проблемы вместо её корневой причины, а также, быстрее находить первопричину.
Например, если сервер выходит из строя из-за перегрева, система AIOps определяет, что проблема вызвана неисправностью в системе охлаждения, и предлагает перенаправить рабочую нагрузку на другие серверы до устранения неисправности.
Обнаружение аномалий
Инструменты AIOps способны анализировать значительные объемы исторических и потоковых данных, выявлять нетипичные наблюдения, последовательности событий и плотность нагрузки. Это помогает командам идентифицировать и прогнозировать проблемные события и предотвращать их потенциально дорогостоящие последствия (негативный PR, штрафы…).
Например, при неожиданном скачке сетевого трафика AIOps может определить, что причиной является несанкционированная загрузка данных, и автоматически заблокировать подозрительную активность, предотвращая потенциальную утечку информации.
Мониторинг производительности приложений
AIOps предоставляет полную картину производительности всех компонентов IT-инфраструктуры, объединяя данные о серверах, сетях и системах хранения.
Например, в разгар крупной распродажи на e-commerce платформе система фиксирует замедление обработки заказов из-за перегрузки базы данных, автоматически масштабирует ресурсы и сохраняет скорость транзакций на высоком уровне, улучшая пользовательский опыт.
Управление инфраструктурой
Благодаря анализу в реальном времени AIOps помогает IT-командам эффективно управлять сложной инфраструктурой и оптимизировать использование ресурсов.
Например, система анализирует серверные кластеры и обнаруживает, что часть серверов простаивает без нагрузки. На основе этого AIOps предлагает перераспределить задачи или отключить избыточные ресурсы, что приводит к значительному снижению затрат без ущерба для производительности.
Облачные операции
AIOps обеспечивает управление сложными мультиоблачными средами, автоматически адаптируя их к изменениям нагрузки.
Например, в период высокого спроса система увеличивает мощность облачных ресурсов для обеспечения бесперебойной работы онлайн-кинотеатра, а после окончания пикового времени возвращает ресурсы в стандартное состояние, оптимизируя затраты компании.
Информационная безопасность
AIOps значительно расширяет возможности обнаружения и предотвращения угроз за счёт анализа данных безопасности в режиме реального времени.
Например, система фиксирует аномальную активность, такую как массовые неудачные попытки входа в систему, определяет возможную атаку методом перебора паролей и мгновенно блокирует доступ к учётным записям, предотвращая утечку данных.
Какие типы AIOps существуют?
Существует два основных типа AIOps, каждый из которых ориентирован на определенные потребности бизнеса и задачи IT-инфраструктуры:
Доменно-ориентированный подход
Этот тип решений фокусируется на определенной области IT-операций, предоставляя инструменты, оптимизированные для узконаправленных задач. Например, такие платформы могут быть специализированы на мониторинге производительности сетей, приложений или облачных систем. Эти решения идеально подходят для компаний, которые хотят усилить управление конкретным аспектом своей инфраструктуры.
Доменно-агностический подход
Эти решения имеют более универсальный характер и предназначены для интеграции данных из множества источников. Они способны обеспечивать прогнозную аналитику и автоматизацию операций на уровне всей организации, вне зависимости от границ сетей или подразделений. Доменно-агностические платформы позволяют компании получить целостное представление о своих операциях и принимать стратегические решения на основе собранной информации.
Оба типа AIOps предоставляют уникальные преимущества, и выбор между ними зависит от конкретных целей организации и уровня зрелости её IT-инфраструктуры.
Artimate — российская AIOps-платформа
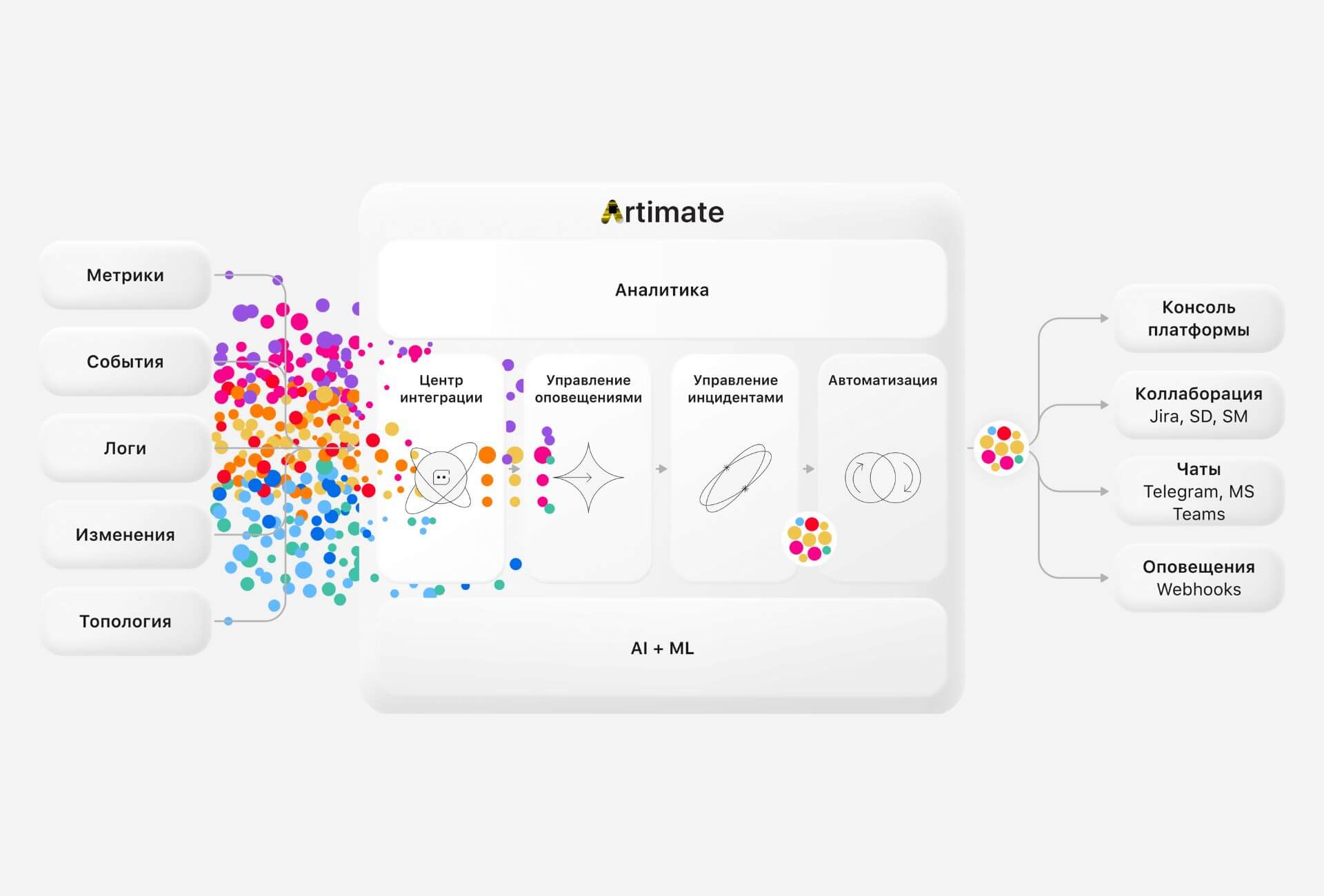
Artimate — аналитическая AIOps-платформа для полного контроля над сложной IT-инфраструктурой.
С помощью технологий искусственного интеллекта и машинного обучения Artimate устраняет информационный шум, фокусируя внимание IT-команд только на действительно важных инцидентах. Она объединяет данные из различных систем, обогащает их контекстом, выявляет основные причины проблем и предлагает оптимальные решения. Это позволяет оперативно реагировать на критические события и эффективно распределять ресурсы для решения приоритетных задач.
В таблице мы расписали, как мы воплощаем и улучшаем AIOps-подход в нашем продукте:
| Направление | Стандартный подход AIOps | Наш подход в Artimate |
| Интеграции | Набор готовых интеграций к различным системам для сбора и обработки:события;alerts;метрики;топология;тикеты;изменения. | Дополнительно:Универсальный low-code коннектор OIM, с помощью которого можно подключить практически любую систему мониторинга — не ограничены готовыми коннекторами.Парсинг логов — LOG-FILE агент. |
| Управление изменениями | Сбор данных с внешних систем (SD, Jira, …). | Дополнительно:Гибкая настройка нормализации статуса поступающих данных с помощью low-code конструктора условий — извлечение событий, связанных с изменениями конфигурации ПО, оборудования, действиями администраторов, … |
| Детекция аномалий | Детекция аномалий временных рядов или адаптивные детекторы для метрик (потока метрик). Позволяет рассчитывать тренды, оценивать прогнозы на основе трендов, реализовать адаптивные пороги при работе с метриками (трейсами метрик). | Расширенный набор детекторов аномалий:Детектор аномалий последовательности (цепочек) событий. Позволяет обнаруживать недостающие ожидаемые события (до, после), задержку событий.Детектор аномалий плотности событий. Позволяет фиксировать избыточно высокую или низкую плотность событий по сравнению с нормальным поведением. Решение позволит фиксировать в т.ч. события в части информационной безопасности.Детектор аномалий временных рядов. |
| Контекстуализация | Обычно используют алгоритмические правила обогащения и конструкторы сценариев work-flow — ручная настройка. | Интеллектуальная работа с неструктурированными данными — поиск скрытых смыслов.Дополнительно используем:ML кластеризация,ML классификацияПомогаем выделить скрытые смыслы, разметить, структурировать, сгруппировать слабоструктурированные, неструктурированные данные, в т.ч. Log-файлы. |
| Корреляция | Использование всех доступных инструментов для оценки корреляции:Алгоритмические шаблоны корреляции.Правила (work-flow) обработки.Ресурсно-сервисная модель (РСМ). | Искусственный интеллект для поиска неявных связей — полная автоматизация.Дополнительно: ML корреляция на базе корреляционных графов — карты причинно-следственных связей.Автоматическое построение ресурсных карт на базе поступающих данных ИТ-мониторинга. |
| Инциденты | Автоматизация работы с инцидентами:Построение истории инцидента (алерты, изменения), Топология на базе РСМ или ручные топологии с заданными или рассчитываемыми весами. | Дополнительно:История инцидента отражает хронологию связанных оповещений, изменений и аномалий.Карта причинно-следственных связей инцидента на базе алгоритмических и ML шаблонов корреляции.Учет несколько типов аномалий в инцидентах.Прогноз развития инцидента. |
| Автоматизация | Автоматизация эскалации и решения инцидентов:Сценарии эскалации, Runbook, Скрипты, Low-code. | Эскалация и устранение симптомов до возникновения проблем:Автоматическая оценка вероятностного прогноза развития инцидента (roadmap), расстановка приоритетов с учетом будущего влияния на критические бизнес-сервисы.Автоматическое построение карт ресурсов на основе поступающих данных.Интеллектуальный помощник (чат-бот) ARTI. |
| Аналитика | Контроль и анализ основных метрик инцидентов:Среднее время обнаружения (MTTD).Среднее время подтверждения (MTTA).Среднее время решения (MTTR). | Дополнительные отчеты по метрикам инцидентов:Доступность сервиса.Оценка уровня снижения информационного шума — соотношение событий к инцидентам.Соотношение автоматического к ручному решению инцидентов.Оценка наиболее критичных компонентов ИТ, их причинно-следственных связей.Комплексный системный анализ узких мест и уязвимостей:Критические компоненты.Критические связи, наборы (цепочки) связей.Автоматическое выделение редких, но значимых событий. |
Убедитесь в возможностях Artimate на практике! Запишитесь на демо, чтобы увидеть, как платформа поможет вашему бизнесу улучшить стабильность IT-систем и сократить время решения инцидентов.
