Обогащение данных в мониторинге: от информационного шума к инсайтам
Современные ИТ-системы генерируют объемы телеметрии, превышающие возможности человеческого анализа. Команды эксплуатации (Ops) и разработки (Dev) получают тысячи алертов ежедневно из десятков разрозненных инструментов мониторинга. Проблема в том, что большая часть этих данных представляет собой изолированные сигналы без контекста.
Результат предсказуем: перегрузка информацией, замедление реакции на инциденты и рост операционных издержек. Согласно исследованиям, инженеры тратят до 40% рабочего времени не на решение проблем, а на поиск информации, необходимой для их понимания.
Обогащение данных решает эту проблему, превращая фрагментированную телеметрию в действенную информацию для принятия решений. Это ключевой элемент перехода от классического мониторинга к полноценной наблюдаемости.
В этой статье мы разберем техническую суть обогащения данных, его влияние на ключевые метрики эффективности, основные технологии реализации и способы преодоления сложностей внедрения.
Определение и механизм обогащения данных
Обогащение данных — это процесс дополнения сырой информации релевантным контекстом из внутренних и внешних источников для повышения ее аналитической ценности.
Простыми словами: если сырой алерт — это кусок пазла, то обогащенные данные — это собранная картина.
В контексте ИТ-операций это означает трансформацию базового уведомления (код ошибки, временная метка, ID хоста) в полноценное досье инцидента. Оно включает информацию о зависимостях систем, истории подобных сбоев, потенциальном влиянии на бизнес-процессы и рекомендуемых действиях.
Как это работает на практике: 5 этапов конвейера данных
Процесс обогащения не происходит мгновенно, это выстроенный конвейер обработки информации:
- Сбор сырых данных.
Агрегация информации из систем мониторинга (Zabbix, Prometheus и других), логов приложений, сетевых устройств и облачных платформ. На этом этапе данные фрагментированы: вы видите, что «сервер упал», но не знаете почему.
- Корреляция с дополнительными источниками.
Сопоставление сырых данных с метриками производительности, историческими логами, конфигурациями систем (CMDB) и данными из сторонних инструментов (Jira, ServiceNow).
Пример: корреляция пика CPU с недавним деплоем кода или внешними сетевыми проблемами выявляет паттерны и причинно-следственные связи, которые иначе остались бы скрыты.
- Добавление контекста и метаданных.
Обогащение данных уровнем критичности, идентификаторами затронутых бизнес-сервисов, владельцами команд, SLA и историческим временем разрешения аналогичных инцидентов.
Сценарий: Если код ошибки появляется регулярно с типичным временем решения 30 минут, система автоматически присваивает инциденту низкий приоритет. Если же ошибка новая и затрагивает платежный шлюз — приоритет становится критическим.
- Визуализация и представление.
Трансформация данных в удобный формат: интеллектуальные алерты, дашборды, топологические карты. Критическая информация (затронутые системы, вероятная причина, runbook) выделяется визуально, чтобы инженер мог считать ситуацию за секунды.
- Интеграция с операционными инструментами.
Передача обогащенных данных в системы автоматизации, тикетинга и управления инцидентами. Это позволяет запускать workflow автоматически: например, создать тикет в Jira с уже заполненным описанием или перезапустить зависший сервис.
Влияние на операционные метрики
Внедрение обогащения данных измеряется через конкретные показатели эффективности ИТ-операций.
Сокращение MTTR. Компании, использующие системы с автоматическим обогащением и корреляцией данных, достигают 94% точности корреляции алертов и сокращают MTTR на 60% в течение двух месяцев. Автоматическое добавление контекста устраняет необходимость ручного поиска информации, который занимает значительную часть времени разрешения инцидентов.
Снижение объема алертов. Агрегация связанных событий в единый высокоуровневый инцидент сокращает шум и позволяет администраторам эффективнее реагировать на проблемы. Системы корреляции с обогащением данных демонстрируют точность распознавания множественных коррелированных алертов на уровне precision = 0.92, recall = 0.93, F1-score = 0.93.
Ускорение триажа. Обогащенные данные предоставляют критический контекст (зависимости систем, исторические тренды, влияние на бизнес) необходимый для быстрой оценки и приоритизации инцидентов. Команды принимают решения на основе реального воздействия, а не тратят время на сбор базовой информации.
Улучшение анализа первопричин. Контекст о предшествующих событиях и системных зависимостях позволяет быстрее определять root cause, сокращая циклы повторного troubleshooting. Корреляция метрик, логов и трейсов с контекстуальными данными ускоряет выявление причинно-следственных связей и исправление проблем на уровне кода.
Технологические подходы к обогащению
Как технически реализуется этот процесс в современных стеках?
Интеграция с источниками телеметрии.
Современные платформы наблюдаемости интегрируют 500+ источников данных (метрики, логи, трейсы) для создания единого представления IT-инфраструктуры. Они собирают телеметрию из облачных сервисов, систем управления конфигурациями и APM-инструментов в модель топологии реального времени.
Автоматизация сбора данных.
Технологии вроде eBPF позволяют автоматически собирать гранулярные данные на уровне ядра (полные payloads, HTTP-заголовки, query-параметры, обогащенные атрибуты) без ручной инструментации. Это закрывает пробелы традиционных OpenTelemetry-реализаций и устраняет сложность ручной настройки.
Искусственный интеллект и машинное обучение.
Алгоритмы ML анализируют огромные датасеты, выявляют аномалии и паттерны, предсказывают потенциальные проблемы на основе исторических данных. Нейросетевые модели обучаются на исторических последовательностях событий и детектируют коррелированные сбои в режиме онлайн, часто предвосхищая инцидент.
Топологический мэппинг.
Визуализация зависимостей между компонентами инфраструктуры упрощает понимание влияния инцидентов и отслеживание первопричин. Семантические связи между сущностями — логи, метрики, сервисы — структурируются для более быстрого поиска и корреляции.
Бизнес-ценность обогащения данных
Обогащение данных фундаментально меняет подход к надежности сервисов, позволяя перейти от реактивного устранения сбоев к их профилактике. Анализ обогащенных исторических метрик и системных трендов выявляет скрытые паттерны деградации еще до того, как они приведут к остановке бизнеса. Платформы с элементами искусственного интеллекта используют эту предиктивную аналитику для превентивных действий, что напрямую влияет на стабильность систем и сохранение выручки, предотвращая простои до их наступления.
Параллельно трансформируется и процесс обработки инцидентов, который становится более точным и менее затратным по вниманию инженеров. Обогащенные алерты перестают быть сухими сигналами: они содержат контекст предыдущих событий и детальные данные о триггерах, что интеллектуально фильтрует шум и снижает количество ложных срабатываний. Кластеризация связанных событий позволяет командам не распыляться на второстепенные уведомления, а фокусироваться исключительно на критических проблемах, действительно влияющих на пользователей.
Накопленный структурированный контекст становится надежным фундаментом для масштабирования автоматизации операций. Когда данные очищены и дополнены метаданными, инструменты автоматизации могут безопасно выполнять сложные сценарии: от запуска workflow разрешения инцидентов до профилактических проверок и создания тикетов с полным описанием проблемы. Это освобождает квалифицированные команды от рутинных операций, позволяя перераспределить ресурсы на стратегические задачи развития инфраструктуры вместо поддержки текущей деятельности.
Проблемы внедрения и решения
Внедрение обогащения данных — это стратегическая инициатива, которая неизбежно сталкивается с рядом технических и организационных барьеров. Фундаментальной проблемой остается качество и консистентность входных данных: неполные или устаревшие сырые данные не просто бесполезны, они создают ложную картину происходящего, превращая инструмент решения проблем в источник новых ошибок. Чтобы избежать принципа «garbage in, garbage out», необходимо внедрять строгую валидацию данных уже на этапе сбора и проводить регулярный аудит источников информации.
Следующим препятствием становится интеграция с существующим ландшафтом инструментов. Различия в форматах данных между разрозненными платформами мониторинга часто затрудняют создание единого контекста. Современные подходы решают эту задачу через унифицированные API, поддержку открытого стандарта OpenTelemetry и использование готовых коннекторов к популярным системам, что позволяет абстрагироваться от вендорских особенностей и объединить данные в единый поток.
По мере роста инфраструктуры на первый план выходит вопрос масштабируемости. Экспоненциальный рост объемов телеметрии требует архитектуры, способной обрабатывать потоки данных в реальном времени без задержек. Оптимальным решением становятся гибкие системы, способные автоматически изменять вычислительные мощности под текущую нагрузку. Это позволяет обрабатывать растущие объемы данных в реальном времени без пропорционального увеличения расходов.
Важно также не полагаться на автоматизацию слепо. Алгоритмы могут упустить важные детали, которые очевидны для опытного инженера, но не видны машине. Поэтому эффективнее автоматизировать рутинные задачи, а ключевые решения оставлять за специалистами. Такой подход позволяет сохранить контроль над ситуацией и избежать ошибок, которые могут возникнуть при полной передаче задач алгоритмам.
Лучшие практики внедрения
Успешное внедрение обогащения данных требует стратегического подхода, где технология вторична по отношению к качеству метаданных. Фундаментом успеха является стандартизация тегирования: если в вашей CMDB или облачных ресурсах отсутствуют актуальные владельцы сервисов, бизнес-единицы и уровни критичности, система обогащения не сможет корректно распределить приоритеты. Поэтому первым шагом должен стать аудит и «гигиена» метаданных, а не покупка нового ПО. Без надежной основы в виде структурированных тегов даже самые продвинутые алгоритмы будут работать некорректно.
Далее важно применить принцип критического пути. Попытка обогатить данные всей инфраструктуры сразу приведет к перегрузке команд и неконтролируемому росту затрат. Вместо этого выберите топ-5 сервисов, напрямую влияющих на выручку, и настройте глубокий контекст именно для них. Это позволит быстро продемонстрировать ценность подхода, отработать механику на ограниченном, но важном участке системы и избежать паралича анализа на старте.
Третий ключевой аспект — построение цикла обратной связи с инженерами. Обогащение данных должно решать их проблемы, а не создавать новые. Регулярно собирайте фидбек: помогают ли дополнительные поля быстрее находить причину? Не стало ли слишком много информации? Это позволит калибровать систему так, чтобы она действительно экономила время, а не просто генерировала красивые дашборды. Воспринимайте обогащенные данные как внутренний продукт, где пользователи — ваши операторы и разработчики.
Наконец, нельзя игнорировать экономическую эффективность. Хранение и обработка обогащенных данных стоят денег. Необходимо четко разграничивать «горячие» данные, требующие полного контекста в реальном времени, и «холодные» архивы, где детализация может быть снижена. Грамотное управление жизненным циклом данных предотвратит ситуацию, когда стоимость системы мониторинга превысит ущерб от предотвращенных инцидентов.
AIOps-платформа Artimate: процесс обогащения данных мониторинга
Что такое Artimate?
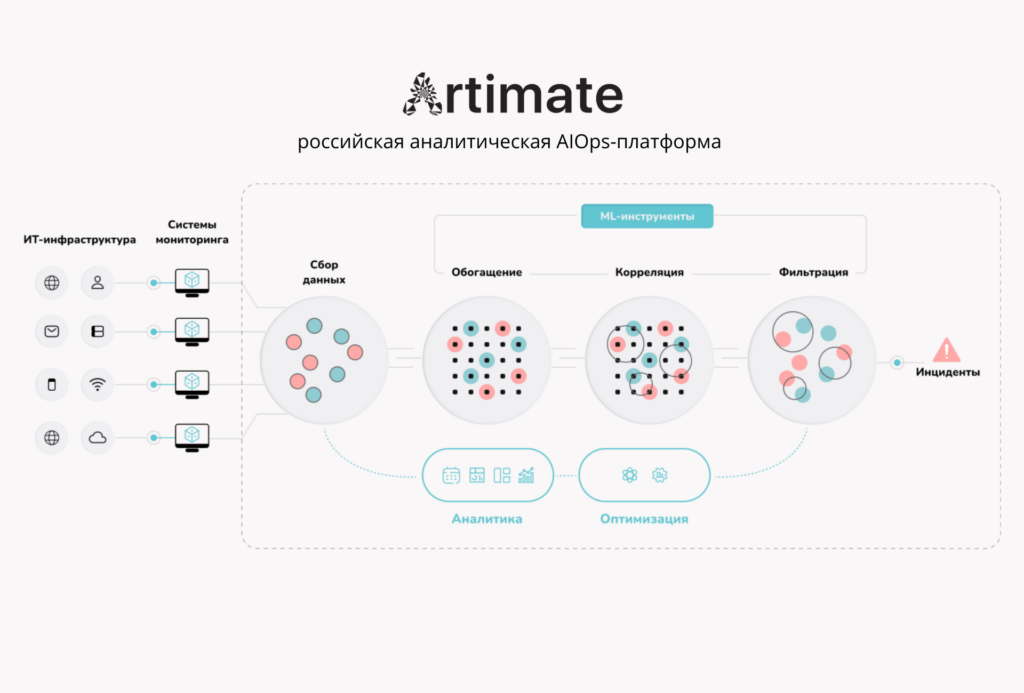
Artimate — это интеллектуальная AIOps-платформа, использующая искусственный интеллект и машинное обучение для автоматической обработки и анализа большого объема событий из систем ИТ-мониторинга, объединения инцидентов в единую картину, визуализации причинно-следственных связей и прогнозирования сбоев.
Это единый интерфейс, в котором собираются данные со всех систем мониторинга, а встроенные инструменты ML-анализа и управления помогают быстро находить причины сбоев, принимать решения и предотвращать инциденты до их влияния на бизнес-сервисы.
Жизненный цикл данных в Artimate
Artimate превращает потоки сырых данных в четко определенные инциденты — каждый по своей проблеме. Эти этапы могут быть как простым устранением дубликатов, так и сложными ML операциями по структурированию данных.
Проще всего жизненный путь данных понять на примере:

Для достижения этого в Artimate предусмотрены два этапа: создание пайплайна (настройка системы) и его эксплуатация.
Создание пайплайна
- В случае алгоритмической части системы — это создание интеграций, правил нормализации, агрегации и дедупликации, правил обогащения, шаблонов и прочих настроек. Происходит мгновенно;
- В случае ML части системы — это обучение моделей кластеризации, корреляции и детекции аномалий на наборах исторических данных. Требует расчёта ML-моделей.
Эксплуатация пайплайна
Алгоритмическая и ML части применяются схожим образом:
- обогащение событий производится алгоритмически или с ML (классификация, детекция аномалий);
- шаблоны бывают алгоритмическими или ML-шаблонами (корреляция).
Интеллектуальное обогащение событий контекстом в Artimate
Оповещения (alerts) — это события, которые считаются важными для рассмотрения. Это могут быть ошибки, предупреждения, изменения. Их важно обогащать тэгами (метками) для эффективности следующего этапа — связывания оповещений в инциденты.
Обогащение исходных событий в Artimate происходит путем присвоения дополнительных тегов и контекстной информации. Когда в систему поступает алерт с базовой меткой application:payment-service, платформа автоматически добавляет связанную информацию:
- Инфраструктурный контекст: server:k8s-node-03, cluster:prod-payments, datacenter:msk-01;
- Топологический контекст: upstream:user-auth, downstream:bank-gateway, database:payments-db;
- Временной контекст: deployment:release-v2.1.4, rollback_window:active, maintenance_schedule:none.
Такое многослойное обогащение позволяет алгоритмам корреляции работать не только на уровне отдельных сервисов, но и анализировать взаимосвязи между различными уровнями абстракции: от физических серверов до бизнес-процессов.
Например, алерт о высокой загрузке процессора обогащается информацией о недавних изменениях на этом сервере из системы управления изменениями, данными о бизнес-сервисах, которые работают на этом хосте, и метриками зависимых компонентов. Это позволяет платформе не просто фиксировать отдельные события, а видеть полную картину происходящего в инфраструктуре.
Алгоритмические правила обогащения
Обогащение оповещений с помощью алгоритмических правил:
- Назначение (Appointment) оповещениям, подходящим под заданные фильтры, пары тег-значение.
- Извлечение (Extraction) значений тегов с помощью выражений Regex из содержания заданных тегов.
- Сопоставление (Mapping) значений тегов по таблицам соответствия.
ML-кластеризация, классификация, поиск аномалий
ML-кластеризация предоставляет инструменты для автоматического выявления структуры неструктурированных данных с помощью различных методов машинного обучения.
ML-классификация позволяет размечать события структурой, созданной на этапе кластеризации, навешивая на них теги.
Поиск аномалий позволяет на основе анализа данных нормального поведения системы автоматически находить: аномалии плотности событий, аномалии временных рядов, аномалии цепочки событий.
Фильтрация оповещений
Настройка правил фильтрации избыточных оповещений с помощью графического low-code конструктора.
Заключение
Обогащение данных знаменует собой конец эры простого сбора телеметрии и начало эры управленческих инсайтов. Это не просто техническая оптимизация, а стратегический рычаг, который превращает разрозненные сигналы в единую картину здоровья бизнеса. Внедрение этих практик позволяет не только сократить время восстановления и устранить информационный шум, но и фундаментально изменить культуру эксплуатации — от постоянного реагирования на сбои к гарантированию стабильности сервисов. В мире, где сложность инфраструктуры растет экспоненциально, контекст становится самой ценной валютой. Инвестиции в обогащение данных — это не расходы на инструменты, а вклад в устойчивость бизнеса, где каждый инцидент понимается быстрее, а каждое решение подкреплено фактами, а не догадками.
