
В последние годы стремительный рост данных и усложнение ИТ-инфраструктуры сделали ИТ-мониторинг одной из ключевых задач для стабильной работы компаний. От серверов и баз данных до облачных решений и бизнес-приложений – каждый компонент системы должен функционировать бесперебойно, ведь даже малейший сбой может привести к финансовым потерям и простою бизнеса.
Однако традиционные методы мониторинга, основанные на статических правилах и ручном управлении, уже не справляются с объемами современных данных и их обработкой. Чтобы оперативно выявлять проблемы, предсказывать сбои и оптимизировать процессы, на помощь приходят технологии искусственного интеллекта и машинного обучения. Эти инструменты позволяют компаниям перейти от реактивного подхода к интеллектуальному проактивному мониторингу, что существенно снижает риски и затраты.
В этой статье мы разберём, почему AI и ML стали необходимыми для ИТ-мониторинга, как они работают на практике, и какие преимущества они предоставляют современному бизнесу.
Что такое ИТ-мониторинг и его главные задачи?
Современные компании всё больше зависят от информационных технологий: от баз данных и серверов до облачных сервисов и бизнес-приложений. В этой экосистеме даже незначительный сбой может привести к простою, финансовым потерям и репутационному ущербу. Чтобы избежать таких проблем, организации внедряют ИТ-мониторинг – системы, которые отслеживают состояние инфраструктуры, производительность оборудования и работоспособность приложений.
ИТ-мониторинг – это процесс непрерывного наблюдения за ключевыми компонентами ИТ-инфраструктуры для обеспечения их стабильной и бесперебойной работы. Он охватывает сбор и анализ данных о состоянии серверов, сетевого оборудования, баз данных, бизнес-приложений и облачных сервисов. Главная цель мониторинга – оперативное выявление и устранение проблем до того, как они повлияют на производительность системы.
Среди ключевых задач ИТ-мониторинга можно выделить обнаружение проблем в реальном времени, что позволяет быстро фиксировать сбои и неполадки на ранних этапах. Важнейшей функцией также является предотвращение простоев: системы мониторинга помогают минимизировать время на восстановление и устранять инциденты до их масштабного развития. Кроме того, мониторинг играет ключевую роль в оптимизации производительности, обеспечивая стабильную работу приложений и их быструю реакцию на запросы. Особое внимание уделяется вопросам безопасности: выявление аномальной активности или потенциальных угроз помогает защитить данные и предотвратить кибератаки. Наконец, с помощью анализа собранной информации мониторинг позволяет выявлять закономерности в работе систем и прогнозировать потребности в ресурсах для долгосрочного планирования.
На первый взгляд, мониторинг может казаться простой задачей: установить систему, которая будет отправлять уведомления в случае проблем. Однако на практике всё гораздо сложнее.
Чем крупнее компания, тем сложнее ИТ-мониторинг
С ростом бизнеса увеличивается не только объём данных, но и сложность инфраструктуры. В крупных компаниях есть десятки, а иногда и сотни систем, которые нужно контролировать одновременно:
- Серверы: физические и виртуальные.
- Сети: маршрутизаторы, коммутаторы, каналы передачи данных.
- Базы данных: огромные хранилища с критически важной информацией.
- Облачные решения: SaaS, PaaS и IaaS-платформы.
- Приложения: бизнес-сервисы, CRM и ERP-системы и так далее.
Каждый из этих элементов должен быть доступен, стабилен и безопасен. Но с ростом числа пользователей, запросов и процессов инфраструктура становится всё более уязвимой и подверженной сбоям.
Например, в крупной компании миллионы операций происходят каждую минуту. Любая задержка в обработке данных или сбой сервера может вызвать цепную реакцию: замедление работы приложений, простои для сотрудников и клиентов, а в итоге – финансовые убытки.
Традиционные методы ИТ-мониторинга уже не справляются с таким объёмом информации и сложностью процессов обработки данных. Здесь на помощь приходят искусственный интеллект и машинное обучение.
Почему традиционные подходы к ИТ-мониторингу устаревают?

На протяжении десятилетий ИТ-мониторинг базировался на статических правилах и ручном управлении. Например, если сервер перегружался или приложение давало сбой, система мониторинга автоматически отправляла уведомление специалисту. Однако такой подход был эффективен лишь в условиях менее сложных ИТ-инфраструктур, когда количество систем и взаимосвязей между ними было минимальным. В условиях современного бизнеса, где объёмы данных растут экспоненциально, а технологии усложняются с каждым годом, традиционные методы мониторинга больше не справляются с поставленными задачами.
Одной из наиболее серьёзных проблем становится шум от ложных срабатываний. Статические правила не учитывают сложные зависимости между компонентами инфраструктуры и контекст происходящих событий. Например, незначительное отклонение в одном из параметров, которое не несёт угрозы, может быть воспринято как критическая ошибка. В результате специалисты ИТ-отдела тратят время на разбор инцидентов, которые на самом деле не требуют вмешательства. По оценкам Gartner, в крупных компаниях до 40% уведомлений оказываются ложными, что ведёт к потере продуктивности и отвлекает команды от более важных задач.
Другой недостаток заключается в невозможности предсказать сбои. Традиционные системы фиксируют только уже произошедшие проблемы, что делает их подход реактивным, а не проактивным. Например, сбой базы данных или перегрузка сервера проявляются лишь в момент их возникновения, когда бизнес уже сталкивается с простоем. В отчёте Forrester Research отмечается, что компании теряют десятки тысяч долларов за каждую минуту простоя критически важной системы. Ситуация усугубляется тем, что отсутствие механизмов прогнозирования не позволяет предотвратить сбои заранее.
С ростом бизнеса и увеличением числа подключённых систем становится очевидной проблема масштабируемости. Современные ИТ-инфраструктуры включают тысячи серверов, сетевых компонентов, баз данных и облачных сервисов, которые взаимодействуют друг с другом в реальном времени. Только в одной крупной организации количество событий, требующих мониторинга, может достигать миллиардов в день. Ручное управление таким объёмом информации становится не только неэффективным, но и невозможным. По данным исследования IDC, к 2025 году объём глобального ИТ-трафика вырастет на 61%, что сделает ручной мониторинг практически бесполезным.
Наконец, человеческий фактор остаётся слабым звеном в традиционных методах ИТ-мониторинга. Даже опытные специалисты не способны обрабатывать огромные массивы данных и выявлять сложные корреляции между событиями в реальном времени. Более того, многозадачность и высокая нагрузка приводят к снижению концентрации и увеличению вероятности ошибок. Исследование McKinsey показывает, что в среднем 20% критических инцидентов остаются незамеченными из-за перегрузки ИТ-специалистов.
Огромные объёмы данных, сложность ИТ-инфраструктур и высокая стоимость простоев требуют новых решений, способных не только фиксировать проблемы, но и предсказывать их заранее. Именно поэтому компании переходят к внедрению систем на основе искусственного интеллекта и машинного обучения, которые позволяют сделать мониторинг интеллектуальным, масштабируемым и проактивным. Такие системы получили название AIOps-платформы.
AIOps: искусственный интеллект и машинное обучение в ИТ-мониторинге
В последние годы интерес к искусственному интеллекту и машинному обучению стремительно вырос. Согласно отчёту компании McKinsey, глобальные инвестиции в ИИ-технологии за последние 5 лет увеличились в четыре раза, а к 2030 году их вклад в мировую экономику составит 15,7 триллиона долларов. От умных голосовых помощников и автопилотов до алгоритмов, предсказывающих финансовые рынки – ИИ и ML проникают во все сферы жизни и бизнеса.
Индустрия ИТ-мониторинга также не осталась в стороне. Если ещё несколько лет назад мониторинг инфраструктуры строился на статических правилах и требовал постоянного вмешательства специалистов, то сегодня искусственный интеллект и машинное обучение позволяют превратить его в интеллектуальный инструмент, который анализирует, предсказывает и оптимизирует процессы в режиме реального времени.
Искусственный интеллект – это набор технологий, которые позволяют системам выполнять задачи, традиционно требующие человеческого интеллекта. К ним относятся анализ больших объёмов данных, выявление закономерностей и принятие решений на основе полученной информации. В ИТ-мониторинге ИИ играет роль интеллектуального «мозга», который обрабатывает многомерные данные в реальном времени и помогает быстро выявлять угрозы и узкие места в инфраструктуре.
Машинное обучение, в свою очередь, является одним из направлений ИИ и позволяет системам обучаться на основе исторических данных, улучшая свою производительность без прямого программирования. В контексте ИТ-мониторинга ML используется для автоматического поиска аномалий, предсказания вероятных сбоев и оптимизации работы инфраструктуры. Это достигается благодаря способности алгоритмов «учиться» на накопленной информации о поведении компонентов системы и адаптироваться к новым условиям.
Принципы работы ИИ и ML в ИТ-мониторинге
Сбор данных
На первом этапе AIOps-система собирает данные о работе всех компонентов ИТ-инфраструктуры. Это могут быть метрики производительности серверов (загрузка CPU, объем использованной памяти, дисковое пространство), сетевые показатели (пропускная способность, задержки, потери пакетов), логи приложений и активность пользователей.
Для эффективного мониторинга данные собираются непрерывно и в огромных объёмах. Например, крупный дата-центр может генерировать до 50 Терабайт логов в день. AIOps-платформа применяет агенты сбора данных и API-интеграции, которые позволяют агрегировать информацию в режиме реального времени, создавая полную картину состояния инфраструктуры.
Анализ и обработка данных
После сбора данных платформа переходит к их анализу. На этом этапе используются алгоритмы машинного обучения, которые проводят структуризацию и обработку информации для выявления закономерностей и корреляций.
Ключевой особенностью является способность искусственного интеллекта обрабатывать неструктурированные данные (логи, тексты сообщений об ошибках) и совмещать их с метриками производительности. Например, алгоритмы могут обнаружить связь между увеличением нагрузки на CPU и ростом числа отказов в определённом приложении.
Для этого применяются технологии кластеризации и классификации, такие как:
- K-Means для группировки схожих данных,
- Random Forest и Decision Trees для анализа зависимостей,
- Deep Learning (глубокое обучение) для сложных и многомерных данных.
Такая обработка позволяет выявить скрытые проблемы и паттерны, которые традиционными методами просто не видны.
Выявление аномалий
Один из важнейших этапов – это автоматическое выявление аномалий. Искусственный интеллект использует исторические данные для создания «нормальной» модели поведения системы. Когда показатели начинают отклоняться от этой модели, ИИ фиксирует аномалию.
Например, если средний уровень загрузки процессора сервера колеблется между 40-60%, а внезапно поднимается до 90% без видимых причин, система немедленно сигнализирует об отклонении. Традиционные инструменты мониторинга фиксировали бы такое событие лишь при превышении заранее установленного порога, но ИИ анализирует контекст и сравнивает данные со всей инфраструктурой.
Применяемые методы:
- Supervised Learning (обучение с учителем) для обнаружения известных проблем;
- Unsupervised Learning (обучение без учителя) для выявления новых, неизвестных аномалий.
Предсказание сбоев
На основе собранных данных и выявленных закономерностей алгоритмы машинного обучения могут прогнозировать проблемы, которые ещё не произошли.
Например, искусственный интеллект может предсказать сбой оборудования на основе постепенного ухудшения его метрик: повышение температуры, снижение скорости обработки или рост числа ошибок. В результате компании получают возможность заменить или починить оборудование до его выхода из строя, что значительно снижает простои и издержки.
Прогностический анализ основан на методах Time Series Analysis (анализ временных рядов) и использовании Recurrent Neural Networks (RNN), которые учитывают динамику изменений данных во времени.
Автоматизация принятия решений
Финальный этап – автоматическая реакция системы на выявленные инциденты. ИИ может не только оповещать специалистов, но и самостоятельно предпринимать меры для устранения проблем.
Примеры автоматизированных решений включают:
- Перезапуск сервисов, если приложение перестало отвечать,
- Распределение нагрузки между серверами при обнаружении перегрузок,
- Блокировка подозрительной активности, если ИИ фиксирует угрозу безопасности.
Эти действия выполняются в режиме реального времени с минимальным участием человека, что позволяет значительно сократить время реакции и минимизировать ущерб для бизнеса.
Преимущества искусственного интеллекта и машинного обучения в ИТ-мониторинге

Прогнозирование проблем
Одно из ключевых преимуществ внедрения искусственного интеллекта и машинного обучения в ИТ-мониторинг – это возможность предсказывать сбои и проблемы до их возникновения. Традиционные системы мониторинга фиксируют инциденты постфактум, что требует немедленного вмешательства и зачастую приводит к простою. В отличие от них, алгоритмы машинного обучения анализируют исторические данные, выявляют закономерности и на основе этого прогнозируют потенциальные риски.
Например, ИИ может распознать признаки будущего отказа оборудования по постепенному увеличению температуры, росту числа ошибок ввода-вывода или деградации производительности. Исследование Gartner показывает, что внедрение предиктивного мониторинга позволяет сократить количество неожиданных сбоев инфраструктуры на 45%. В компании GE Aviation, благодаря AIOps-системе, прогнозирование поломок серверов позволило предотвратить простой и сэкономить более 10 миллионов долларов ежегодно.
Сокращение времени простоя
Простои ИТ-инфраструктуры – это один из самых значительных рисков для современных компаний. Согласно данным Ponemon Institute, 1 минута простоя критически важной системы может стоить бизнесу от 5 до 10 тысяч долларов, а для крупных организаций эти цифры достигают 500 тысяч долларов в час.
Мониторинг с применением ИИ и ML позволяет значительно сократить время простоя за счёт мгновенного обнаружения и анализа проблем. Искусственный интеллект выявляет не только сам сбой, но и его корневую причину, анализируя логи и метрики всей инфраструктуры. В результате специалисты получают точную информацию о месте и характере сбоя, что ускоряет процесс его устранения. В компании Netflix, внедрение такого мониторинга позволило снизить время реакции на инциденты с 20 минут до 30 секунд, что позволило обеспечить бесперебойное предоставление сервиса для миллионов пользователей.
Уменьшение нагрузки на специалистов
Современные ИТ-команды часто перегружены рутинными задачами: разбором ложных тревог, анализом метрик и устранением мелких сбоев. По данным отчёта IDC, около 30% рабочего времени специалистов тратится на выполнение повторяющихся задач, которые могут быть автоматизированы.
Искусственный интеллект и машинное обучение позволяют освободить ИТ-специалистов от рутинной работы. Системы автоматически выявляют проблемы, устраняют их или передают точечные оповещения с полным контекстом проблемы. Это позволяет командам сосредоточиться на более стратегических инициативах, таких как цифровая трансформация, разработка новых продуктов или оптимизация процессов. В компании IBM, благодаря внедрению AIOps, объём рутинных задач был снижен на 40%, что повысило продуктивность ИТ-отдела и позволило эффективнее распределить ресурсы.
Повышение точности
Одной из главных проблем традиционного мониторинга является большое количество ложных срабатываний. Статические правила и пороговые значения не учитывают контекст ситуации, что приводит к множеству необоснованных уведомлений. По данным отчёта Forrester Research, до 50% уведомлений в крупных ИТ-системах оказываются ложными.
AIOps-платформы решают эту проблему благодаря способности анализировать многомерные данные и контекст событий. Машинное обучение использует сложные алгоритмы, такие как аномальное поведение (Anomaly Detection) и глубокие нейронные сети, для точной идентификации реальных угроз. Например, AI может различить временное увеличение нагрузки из-за обновления системы и потенциально опасное отклонение, связанное с утечкой памяти.
Такой подход позволяет минимизировать ложные тревоги и снизить количество пропущенных критических инцидентов на 60%. В компании Alibaba, благодаря AIOps, уровень точности обнаружения аномалий достиг 95%, что обеспечило стабильную работу её облачных сервисов.
Оптимизация затрат
Оптимизация затрат – это ещё одно важное преимущество внедрения ИИ и ML в ИТ-мониторинг. Машинное обучение помогает выявлять узкие места, избыточные ресурсы и неэффективное распределение нагрузки в инфраструктуре. Например, ИИ может автоматически распознать серверы с низкой производительностью или выявить неиспользуемые облачные ресурсы, которые можно отключить.
Согласно данным Accenture, компании, внедрившие искусственный интеллект для оптимизации ИТ-инфраструктуры, сократили свои операционные расходы на 20-30% за счёт автоматизации и более эффективного управления ресурсами. В компании Google, внедрение ИИ для управления дата-центрами позволило снизить затраты на охлаждение на 40% благодаря более точному анализу нагрузок и оптимизации распределения энергии.
Российская AIOps-платформа Artimate: ИИ и ML в действии
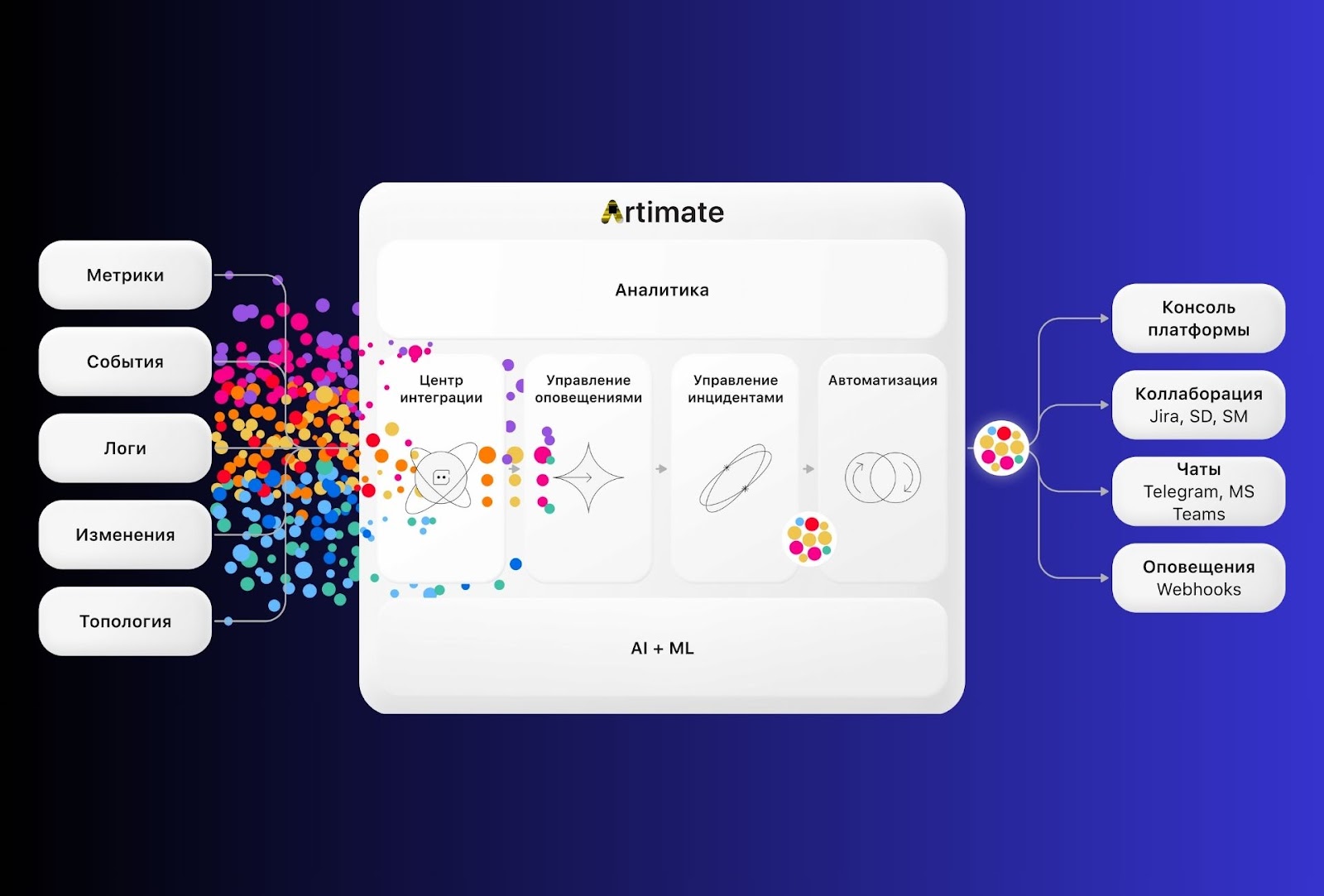
Artimate — это полноценное AIOps-решение, которое использует мощь искусственного интеллекта и машинного обучения для трансформации подхода к управлению IT-инфраструктурой.
Кластеризация
На этапе кластеризации платформа Artimate автоматически группирует большие объёмы похожих событий в понятные и структурированные кластеры. Для этого используются современные большие языковые модели (LLM), которые анализируют и объединяют данные по схожим характеристикам.
Ключевое преимущество Artimate – это возможность гибко редактировать кластеры в процессе работы. В отличие от классических решений машинного обучения, где результаты кластеризации почти не интерпретируемы, здесь вы можете называть, изменять и оптимизировать кластеры под свои потребности за считанные минуты.
Более того, на основе полученных кластеров можно строить карты причинно-следственных связей, что позволяет сделать данные более структурированными уже на этапе кластеризации. Это значительно упрощает понимание данных и работу с ними
Классификация
Этап классификации в Artimate опирается на уже настроенные кластеры. Он позволяет группировать поток событий в реальном времени, обновляя кластеризацию при появлении новых значимых данных. Благодаря этому система адаптируется к изменениям в инфраструктуре и автоматически поддерживает актуальность группировок событий.
Такой подход избавляет от необходимости вручную сортировать новые данные, значительно сокращая время на их обработку и оптимизируя рабочие процессы.
Корреляция
На основе данных кластеризации Artimate создаёт наглядную Карту процессов – графическое отображение причинно-следственных связей между компонентами системы. Эта карта позволяет:
- прогнозировать развитие инцидентов, анализируя влияние одного компонента на другие;
- быстро находить первопричины сбоев;
- выявлять неожиданные зависимости, которые сложно заметить вручную;
- глубже понять работу системы и её внутренние процессы.
Artimate не создаёт хаотичных карт, где «всё связано со всем» (и не предлагает с нуля вручную создавать и поддерживать карты). Платформа использует математические алгоритмы из теории графов и графовые нейронные сети, чтобы автоматически отфильтровать только значимые связи между кластерами. Кластеры отображаются как вершины, а зависимости между ними – как рёбра графа.
Вы получаете полный контроль над картой процессов:
- редактируйте карту в удобном формате;
- настраивайте уровень значимости отображаемых связей;
- анализируйте отдельные компоненты с помощью фильтров;
- отслеживайте развитие сценариев во времени.
Карты обновляются автоматически, что устраняет необходимость вручную пересчитывать связи. Однако вы всегда можете внести правки или настроить карту под свои задачи.
Поиск аномалий
Платформа Artimate – это мощный инструмент для проактивного мониторинга, который позволяет не просто реагировать на инциденты, но и предсказывать их, обеспечивая бесперебойную работу ИТ-сервисов.
Artimate фиксирует аномалии, которые часто остаются незамеченными при традиционном мониторинге:
- локальные изменения в активности компонентов, которые не видны на обобщённых дашбордах;
- нестандартные последовательности событий, скрытые среди сотен штатных операций;
- необычные ситуации, которые невозможно обнаружить вручную;
- аномальное поведение как отдельных метрик, так и их групп, указывающее на потенциальные риски.
Для поиска аномалий применяются передовые методы машинного обучения:
- Invariant Mining – выявление последовательностей корректного поведения системы с использованием математических алгоритмов и ML;
- Графовые нейронные сети – детекция аномалий на уровне взаимодействия кластеров, что позволяет видеть отклонения в работе системы на структурном уровне;
- Рекуррентные нейронные сети (RNN) – обнаружение аномалий в динамике метрик, что особенно эффективно для сложных временных рядов.
Такой подход обеспечивает максимально точное выявление скрытых проблем и позволяет компаниям предотвращать сбои ещё до их возникновения.
Используя машинное обучение на каждом этапе – от кластеризации и классификации до корреляции и поиска аномалий, платформа Artimate позволяет превратить ИТ-мониторинг из рутинного процесса в интеллектуальный инструмент. Artimate помогает глубже понять вашу инфраструктуру, выявить скрытые зависимости, прогнозировать сбои и предотвращать проблемы ещё до их возникновения. Это значит, что бизнес может сосредоточиться на росте и инновациях, а не на бесконечной борьбе с инцидентами.
Хотите увидеть, как это работает на практике? Попробуйте Artimate уже сейчас и убедитесь сами, как машинное обучение и ИИ делают мониторинг быстрее, умнее и эффективнее!
