ИИ в мониторинге ИТ-инфраструктуры: как устроены ML-модели внутри Artimate
Управление современной ИТ-инфраструктурой сталкивается с критическим вызовом масштаба. Распределенные системы генерируют миллионы событий ежедневно, превращая мониторинг в задачу, которую невозможно решить человеческими ресурсами. Традиционные инструменты (регулярные выражения для парсинга логов и статические пороговые значения для метрик) ломаются при первом изменении формата данных или нагрузочного профиля. В микросервисных архитектурах проблема усугубляется: единичный сбой запускает лавину вторичных алертов, которые скрывают истинную первопричину за сотнями ложных срабатываний.
Artimate решает эту проблему через многоуровневую систему машинного обучения, где каждый компонент выполняет специализированную функцию. Далее мы объясним механику каждого компонента этого технологического стека.
Интеллектуальное снижение шума: кластеризация и классификация
Современная ИТ-инфраструктура генерирует «информационное цунами» — тысячи событий в секунду, которые человек физически не способен обработать. Традиционные подходы на основе регулярных выражений (Regex) и статических пороговых значений перестают работать при первом же изменении формата логов разработчиками. Проблема усугубляется в микросервисных архитектурах, где сбой одного компонента запускает каскад алертов, маскирующих истинную первопричину.
Первая задача системы — превратить хаос разнородных логов в упорядоченную структуру. Artimate использует гибридный подход, объединяющий обработку естественного языка (NLP) и статистические методы.
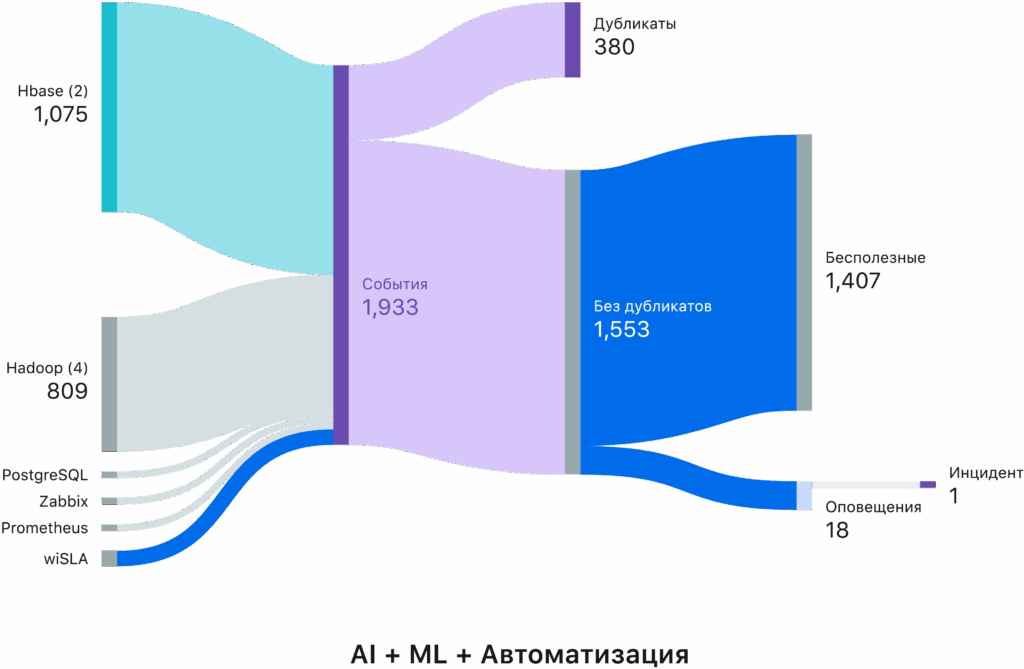
Кейс Artimate по уменьшению информационного шума и структурирования в 1 инцидент
Конвейер обработки состоит из четырех этапов:
Нормализация
Сырые события очищаются от уникального “мусора” (конкретные IP-адреса, ID транзакций, таймстемпы), оставляя только “скелет” сообщения.
Алгоритмическая дедупликация
Мгновенное склеивание полных дублей.
ML-кластеризация (обучение)
На исторических данных модель учится понимать смысл событий. Она группирует похожие логи (например, “Ошибка подключения к БД” и “Логин пользователя в БД неуспешен”) в один смысловой Кластер.
Потоковая классификация
В режиме реального времени (Run-time) новые события мгновенно “раскладываются” по изученным кластерам.
Принципиальное отличие подхода — универсальность. Кластеризация работает одинаково эффективно с событиями любого уровня критичности: от информационных (INFO) до критических (CRITICAL). Модель группирует по смыслу, а не по severity, что позволяет видеть полную картину — и штатную работу системы, и цепочки ошибок.
Ключевая особенность Artimate — механизм Human-in-the-loop. В отличие от систем «чёрного ящика», инженеры получают доступ к результатам кластеризации и могут вручную корректировать ошибки алгоритма. Модель запоминает правки и переучивается, что решает критическую проблему доверия к решениям искусственного интеллекта.
Построение карты связей: графовая корреляция
В микросервисной архитектуре сбой одного компонента вызывает «эффект домино», порождая десятки вторичных алертов. Традиционный мониторинг показывает 100 красных индикаторов, хотя первопричина единственная. Ручная поддержка топологии невозможна — инфраструктура меняется быстрее, чем обновляется документация.
Artimate применяет графовые нейронные сети (GNN) и алгоритмы теории графов для построения динамической карты процессов. Система анализирует временные ряды событий в разных кластерах, выявляя устойчивые зависимости между ними.
Чтобы не создать карту, где “все связано со всем”, применяется жесткий фильтр значимости связей. Например, условная вероятность больше 0,4. Для того, чтобы система зафиксировала связь “Кластер А -> Кластер Б”, ей нужно увидеть этот паттерн примерно 4 раза в условиях повышенного шума (когда много событий происходит почти одновременно — “в одной пачке”), или даже 2 раза, когда плотность событий невысока.
Граф обновляется динамически: если архитектура меняется, старые связи «остывают» и исчезают, новые — укрепляются.
Система строит два типа графов: для нормального поведения (штатные процессы типа «Запрос пользователя → Обращение к кэшу → Ответ») и для аварийных сценариев (цепочки ошибок: «Падение БД → Таймауты API → Отказ фронтенда»). Это позволяет понимать и «здоровье», и «болезни» инфраструктуры.
Вместо списка из 100 алертов оператор видит один Инцидент, в котором подсвечен корневой узел (root cause) и дерево последствий.
Детекция аномалий: увидеть невидимое
Статические пороги типа «CPU > 80%» больше не работают. Они либо «молчат» при деградации сервиса на низкой нагрузке, либо генерируют ложные срабатывания при штатных операциях вроде резервного копирования.
Ансамбль моделей для разных типов данных:
RNN (рекуррентные нейросети) для метрик
Рекуррентные нейросети (RNN) анализируют метрики, запоминая «дыхание» системы — суточные ритмы и недельные циклы нагрузки. Аномалией считается любое нарушение выученного паттерна: если в понедельник утром нагрузка на CPU слишком низкая (хотя должна быть высокой), система регистрирует инцидент, даже если статический порог не превышен.
Invariant Mining (поиск инвариантов) для логов
Система выучивает железные правила: после события «StartTransaction» всегда должен следовать «Commit» или «Rollback». Если после «Start» наступает тишина (обрыв логической цепочки), алгоритм выдает предупреждение, даже если в логах нет явных ошибок уровня ERROR.
GNN для структуры
Графовые нейросети (GNN) анализируют структурные аномалии — изменения паттернов взаимодействия между кластерами. Если два сервиса всегда «общались», а затем внезапно прекратили коммуникацию, это признак проблемы.
Принципиальное отличие детекции аномалий от корреляции: модели обучаются исключительно на нормальном поведении системы. Они не знают, как выглядят ошибки — они знают, как выглядит здоровье. Любое отклонение от выученной нормы считается подозрительным, что позволяет обнаруживать проблемы, которых раньше не было в истории мониторинга.
Синтез: LLM как аналитик
Машинное обучение выдает точные, но трудночитаемые результаты: графы, идентификаторы кластеров, статистические отклонения. Людям нужны выводы на человеческом языке.
Artimate объединяет два подхода: Bottom-up (восходящий анализ через ML) и Top-down (нисходящую интерпретацию через LLM). На стадии Bottom-up машинные алгоритмы выполняют «грязную работу»: разгребает терабайты логов, структурирует их в кластеры (INFO, WARNING, ERROR, …), строит граф инцидента (используя как цепочки ошибок, так и контекст нормального поведения), находит аномалии (отклонения от нормы).
На стадии Top-down в работу включается большая языковая модель. LLM получает подготовленный контекст — гибкую комбинацию данных: события разных типов (ошибки плюс информационные логи для контекста), граф корреляций, обнаруженные аномалии, метрики и их динамику. В зависимости от ситуации, LLM может получать разные срезы данных: только критические события для быстрого анализа, или полную картину с INFO-сообщениями в конкретном временном интервале для глубокого расследования. Это позволяет балансировать между скоростью и детальностью.
Мы получаем точность математических моделей и глубину аналитики генеративного ИИ.
Заключение
Эффективность AIOps-платформы определяется не набором отдельных алгоритмов, а их системной интеграцией. Artimate объединяет NLP-кластеризацию, графовую корреляцию, детекцию аномалий и LLM-аналитику в единый конвейер, который превращает хаос событий в структурированные инсайты.
Современная ИТ-инфраструктура генерирует объемы данных, которые невозможно обработать традиционными методами. Связка ML-моделей позволяет находить закономерности в миллионах событий и выделять критически важную информацию — то, для чего раньше требовались десятки специалистов.
